Programming Guide
Contents
Programming Guide#
Adapters#
The top level abstraction in the unified runtime is the adapter handle. It owns the platform handles as well as any backend specific global state, for instance if a backend has global setup/teardown type entry-points these will typically be tied to the adapter handle’s constructor and destructor.
Adapter handles are reference counted via urAdapterRetain and urAdapterRelease. Once their reference count reaches zero any objects associated with the adapter in question should be considered invalid. Calling urAdapterGet after any adapter handle’s reference count has reached zero will result in undefined behavior. An adapter handle’s reference count may be changed by the adapter itself.
Adapter implementers should ensure the adapter handle is dynamically allocated rather than having a static or global lifetime. Due to how destructor order works for static and global objects this is the only way to ensure the adapter handle stays alive as long as its reference count remains above zero.
Platforms and Devices#
The oneAPI Unified Runtime API architecture exposes both physical and logical abstraction of the underlying devices capabilities. The device, sub-device and memory are exposed at physical level while command queues, events and synchronization methods are defined as logical entities. All logical entities will be bound to device level physical capabilities.
Device discovery APIs enumerate the accelerators functional features. These APIs provide interface to query information like compute unit count within the device or sub device, available memory and affinity to the compute, user managed cache size and work submission command queues.
Platforms#
A platform object represents a collection of physical devices in the system accessed by the same driver.
The application may query the number of platforms installed on the system, and their respective handles, using urPlatformGet.
More than one platform may be available in the system. For example, one platform may support two GPUs from one vendor, another platform supports a GPU from a different vendor, and finally a different platform may support an FPGA.
Platform objects are read-only, global constructs. i.e. multiple calls to urPlatformGet will return identical platform handles.
A platform handle is primarily used during device discovery and during creation and management of contexts.
Platform handles are not reference counted, they are owned by the adapter handle and their lifetime is tied to the adapter handle’s reference count.
Device#
A device object represents a physical device in the system that supports the platform.
The application may query the number devices supported by a platform, and their respective handles, using urDeviceGet.
Device objects are read-only, global constructs. i.e. multiple calls to urDeviceGet will return identical device handles.
A device handle is primarily used during creation and management of resources that are specific to a device.
Device may expose sub-devices that allow finer-grained control of physical or logical partitions of a device.
Device handles are not reference counted, they are owned by their respective platform handles, whose lifetime is in turn tied to the associated adapter handle.
The following diagram illustrates the relationship between the platform, device, context and other objects described in this document.
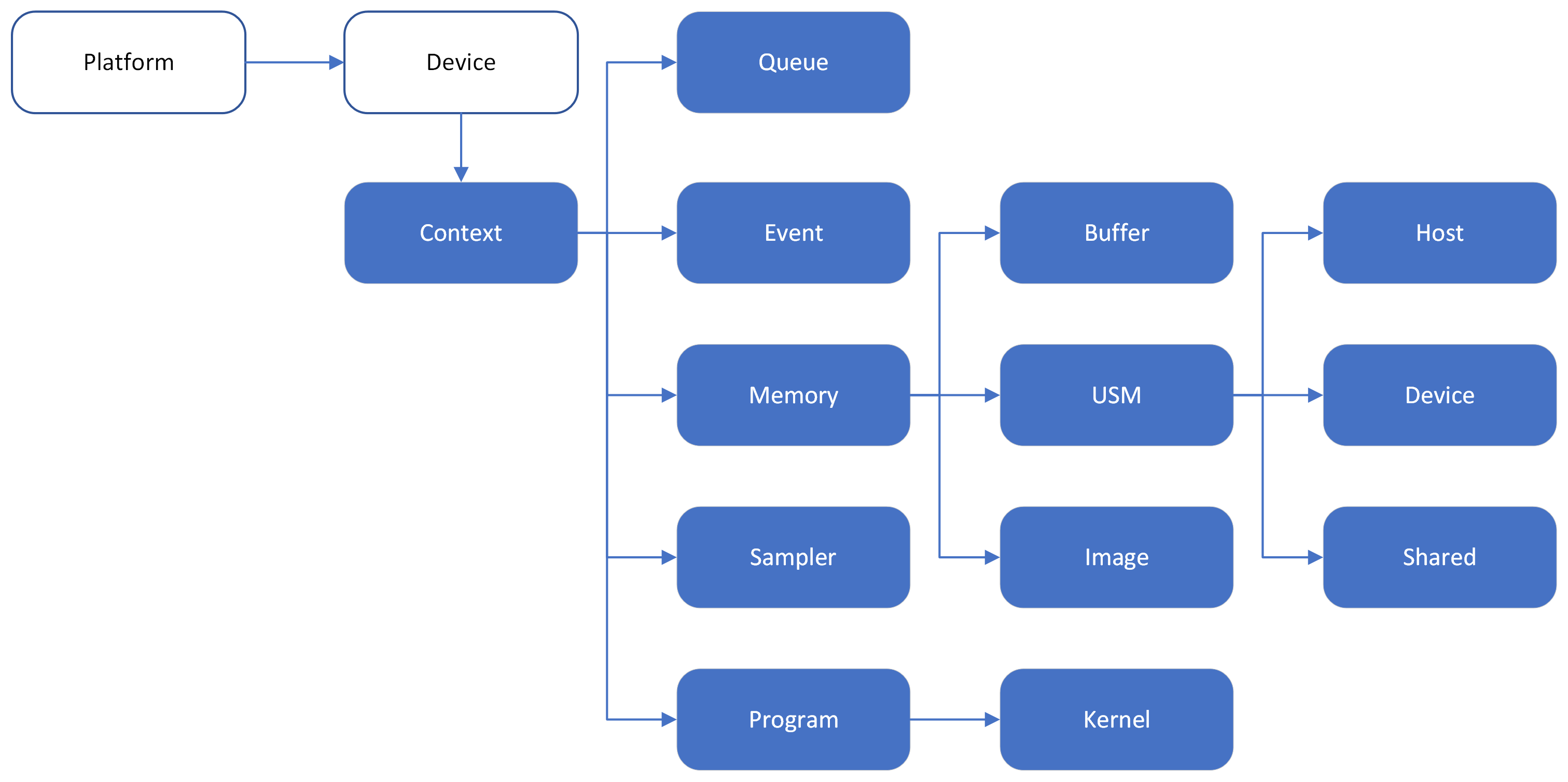
Initialization and Discovery#
// Discover all available adapters uint32_t adapterCount = 0; urAdapterGet(0, nullptr, &adapterCount); std::vector<ur_adapter_handle_t> adapters(adapterCount); urAdapterGet(adapterCount, adapters.data(), nullptr); // Discover all the platform instances std::vector<ur_platform_handle_t> platforms; uint32_t totalPlatformCount = 0; for (auto adapter : adapters) { uint32_t adapterPlatformCount = 0; urPlatformGet(adapter, 0, nullptr, &adapterPlatformCount); platforms.reserve(totalPlatformCount + adapterPlatformCount); urPlatformGet(adapter, adapterPlatformCount, &platforms[totalPlatformCount], &adapterPlatformCount); totalPlatformCount += adapterPlatformCount; } // Get number of total GPU devices in the platform uint32_t deviceCount = 0; urDeviceGet(platforms[0], UR_DEVICE_TYPE_GPU, &deviceCount, nullptr,nullptr); // Get handles of all GPU devices in the platform std::vector<ur_device_handle_t> devices(deviceCount); urDeviceGet(platforms[0], UR_DEVICE_TYPE_GPU, &deviceCount,devices.data(), devices.size());
Retrieve info about device#
The urDeviceGetInfo can return various information about the device. In case where the info size is only known at runtime then two calls are needed, where first will retrieve the size.
// Size is known beforehand ur_device_type_t deviceType; urDeviceGetInfo(hDevice, UR_DEVICE_INFO_TYPE,sizeof(ur_device_type_t), &deviceType, nullptr); // Size is only known at runtime size_t infoSize; urDeviceGetInfo(hDevice, UR_DEVICE_INFO_NAME, 0, &infoSize, nullptr); std::string deviceName; DeviceName.resize(infoSize); urDeviceGetInfo(hDevice, UR_DEVICE_INFO_NAME, infoSize,deviceName.data(), nullptr);
Device partitioning into sub-devices#
urDevicePartition partitions a device into a sub-device. The exact representation and characteristics of the sub-devices are device specific, but normally they each represent a fixed part of the parent device, which can explicitly be programmed individually.
ur_device_handle_t hDevice; ur_device_partition_property_t prop; prop.value.affinity_domain = UR_DEVICE_AFFINITY_DOMAIN_FLAG_NEXT_PARTITIONABLE; ur_device_partition_properties_t properties{ UR_STRUCTURE_TYPE_DEVICE_PARTITION_PROPERTIES, nullptr, &prop, 1, }; uint32_t count = 0; std::vector<ur_device_handle_t> subDevices; urDevicePartition(hDevice, &properties, 0, nullptr, &count); if (count > 0) { subDevices.resize(count); urDevicePartition(Device, &properties, count, &subDevices.data(),nullptr); }
The returned sub-devices may be requested for further partitioning into sub-sub-devices, and so on. An implementation will return “0” in the count if no further partitioning is supported.
uint32_t count; urDevicePartition(subDevices[0], &properties, 0, nullptr, &count); if(count == 0){ // no further partitioning allowed }
Note that unlike a normal device handle, sub-devices are reference counted objects. Their reference count is affected by urDeviceRetain and urDeviceRelease, and once that reference count reaches zero the handle should no longer be considered valid.
Contexts#
Contexts serve the purpose of resource sharing (between devices in the same context), and resource isolation (ensuring that resources do not cross context boundaries). Resources such as memory allocations, events, and programs are explicitly created against a context.
uint32_t deviceCount = 1; ur_device_handle_t hDevice; urDeviceGet(hPlatform, UR_DEVICE_TYPE_GPU, &deviceCount, &hDevice,nullptr); // Create a context ur_context_handle_t hContext; urContextCreate(1, &hDevice, nullptr, &hContext); // Operations on this context // ... // Release the context handle urContextRelease(hContext);
Object Queries#
Queries to get information from API objects follow a common pattern. The entry points for this are generally of the form:
ObjectGetInfo(ur_object_handle_t hObject, ur_object_info_t propName,
size_t propSize, void *pPropValue, size_t *pPropSizeRet)
where propName selects the information to query out. The object info enum
representing possible queries will generally be found in the enums section of
the relevant object.
Some info queries would be difficult or impossible to support for certain backends, these are denoted with [optional-query] in the enum description. Using any enum marked optional in this way may result in UR_RESULT_ERROR_UNSUPPORTED_ENUMERATION if the adapter doesn’t support it.
Some info queries may become deprecated, denoted with [deprecated-value] in the enum description. Using any enum marked as deprecated in this way may result in UR_RESULT_ERROR_INVALID_ENUMERATION if the adapter has ceased to support it.
Programs and Kernels#
There are two constructs we need to prepare code for execution on the device:
Programs serve as containers for device code. They typically encapsulate a collection of functions and global variables represented in an intermediate language, and one or more device-native binaries compiled from that collection.
Kernels represent a handle to a function within a program that can be launched on a device.
Programs#
Programs can be constructed with an intermediate language binary or a device-native binary. Programs constructed with IL must be further compiled through either urProgramCompile and urProgramLink or urProgramBuild before they can be used to create a kernel object.
// Create a program with IL ur_program_handle_t hProgram; urProgramCreateWithIL(hContext, ILBin, ILBinSize, nullptr, &hProgram); // Build the program. urProgramBuild(hContext, hProgram, nullptr);
The diagram below shows the possible paths to obtaining a program that can be used to create a kernel:
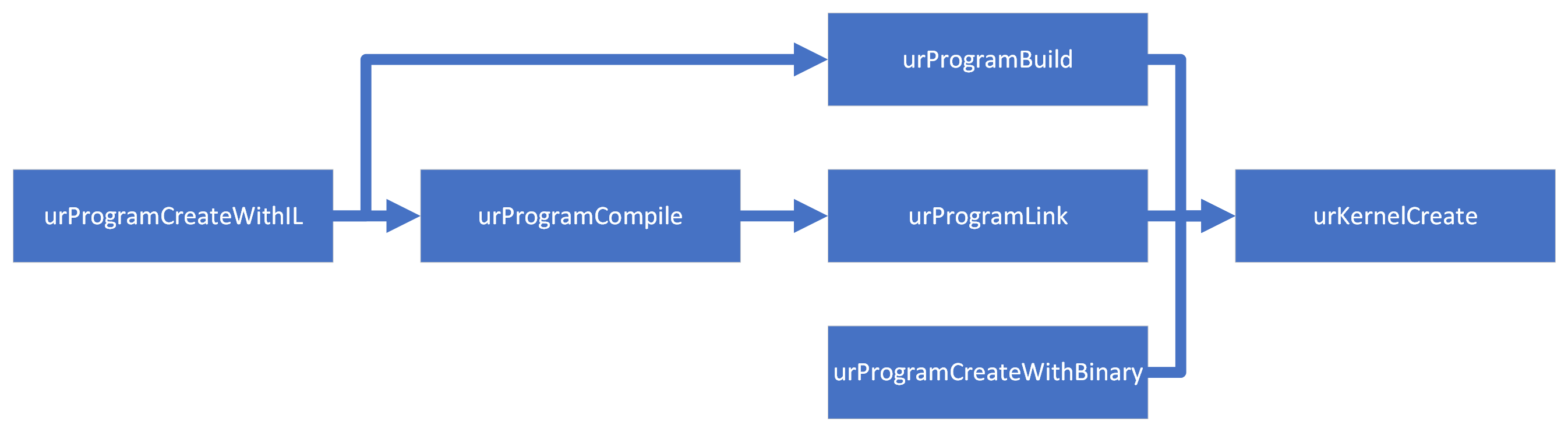
Kernels#
A Kernel is a reference to a kernel within a program and it supports both explicit and implicit kernel arguments along with data needed for launch.
// Create kernel object from program ur_kernel_handle_t hKernel; urKernelCreate(hProgram, "addVectors", &hKernel);
Queue and Enqueue#
Queue objects are used to submit work to a given device. Kernels and commands are submitted to queue for execution using Enqueue commands: such as urEnqueueKernelLaunchWithArgsExp, urEnqueueMemBufferWrite. Enqueued kernels and commands can be executed in order or out of order depending on the queue’s property UR_QUEUE_FLAG_OUT_OF_ORDER_EXEC_MODE_ENABLE when the queue is created. If a queue is out of order, the queue may internally do some scheduling of work to achieve concurrency on the device, while honouring the event dependencies that are passed to each Enqueue command.
// Create an out of order queue for hDevice in hContext ur_queue_handle_t hQueue; urQueueCreate(hContext, hDevice,UR_QUEUE_FLAG_OUT_OF_ORDER_EXEC_MODE_ENABLE, &hQueue); // Launch a kernel with 3D workspace partitioning const uint32_t nDim = 3; const size_t gWorkOffset = {0, 0, 0}; const size_t gWorkSize = {128, 128, 128}; const size_t lWorkSize = {1, 8, 8}; urEnqueueKernelLaunchWithArgsExp(hQueue, hKernel, nDim, gWorkOffset, gWorkSize,lWorkSize, 0, nullptr, nullptr, 0, nullptr, nullptr);
Queue object lifetime#
Queue objects are reference-counted. If an application or thread needs to retain access to a queue created by another application or thread, it can call urQueueRetain. An application must call urQueueRelease when a queue object is no longer needed. When a queue object’s reference count becomes zero, it is deleted by the runtime.
Memory#
UR Mem Handles#
A ur_mem_handle_t can represent an untyped memory buffer object, created by urMemBufferCreate, or a memory image object, created by urMemImageCreate. A ur_mem_handle_t manages the internal allocation and deallocation of native memory objects across all devices in a ur_context_handle_t. A ur_mem_handle_t may only be used by queues that share the same ur_context_handle_t.
If multiple queues in the same ur_context_handle_t use the same ur_mem_handle_t across dependent commands, a dependency must be defined by the user using the enqueue entry point’s phEventWaitList parameter. Provided that dependencies are explicitly passed to UR entry points, a UR adapter will manage memory migration of native memory objects across all devices in a context, if memory migration is indeed necessary in the backend API.
// Q1 and Q2 are both in hContext ur_mem_handle_t hBuffer; urMemBufferCreate(hContext,,,,&hBuffer); urEnqueueMemBufferWrite(Q1, hBuffer,,,,,,, &outEv); urEnqueueMemBufferRead(Q2, hBuffer,,,,, 1, &outEv /phEventWaitList/, );
As such, the buffer written to in urEnqueueMemBufferWrite can be successfully read using urEnqueueMemBufferRead from another queue in the same context, since the event associated with the write operation has been passed as a dependency to the read operation.
Memory Pooling#
The urUSMPoolCreate function explicitly creates memory pools and returns ur_usm_pool_handle_t. ur_usm_pool_handle_t can be passed to urUSMDeviceAlloc, urUSMHostAlloc and urUSMSharedAlloc through ur_usm_desc_t structure. Allocations that specify different pool handles must be isolated and not reside on the same page. Memory pool is subject to limits specified during pool creation.
Even if no ur_usm_pool_handle_t is provided to an allocation function, each adapter may still perform memory pooling.
Native Handles#
In addition to the regular object creation APIs, UR objects can be
constructed with handles obtained directly from an adapter’s associated
backend. This is achieved by casting the backend handle to a
ur_native_handle_t and passing it to the relevant CreateWithNativeHandle
entry point.
Note
Not all backends have a 1:1 equivalent for every UR handle type, as such
any CreateWithNativeHandle or GetNativeHandle entry point may fail
with the error code UR_RESULT_ERROR_UNSUPPORTED_FEATURE for a given
adapter.
Native Handle Ownership#
By default a UR object constructed from a native handle doesn’t own the native handle, it is guaranteed not to retain a reference to the native handle, or cause its resources to be released. A UR object that doesn’t own its associated native handle must be destroyed before the native handle is.
Ownership of the native handle can be transferred to the UR object by passing
isNativeHandleOwned = true in the native properties struct when calling the
CreateWithNativeHandle entry point. A UR object that owns a native handle
will attempt to release the native resources associated with that handle on
destruction. The same native handle must not have its ownership transferred
to more than one UR object.
Ownership of a native handle obtained from a UR object via a
GetNativeHandle entry point must not be transferred to a new UR
object.