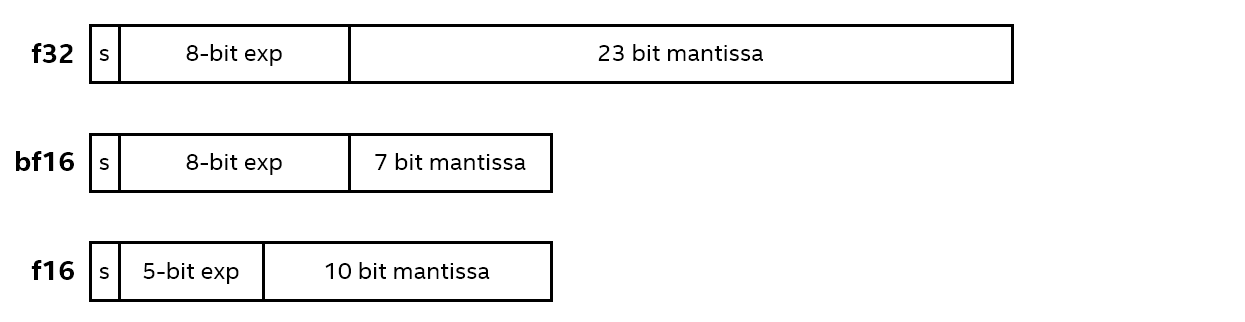
On the path to better performance, a recent proposal introduces the idea of working with a bfloat16 (bf16) 16-bit floating point data type based on the IEEE 32-bit single-precision floating point data type (f32).
Both bf16 and f32 have an 8-bit exponent. However, while f32 has a 23-bit mantissa, bf16 has only a 7-bit one, keeping only the most significant bits. As a result, while these data types support a very close numerical range of values, bf16 has a significantly reduced precision. Therefore, bf16 occupies a spot between f32 and the IEEE 16-bit half-precision floating point data type, f16. Compared directly to f16, which has a 5-bit exponent and a 10-bit mantissa, bf16 trades increased range for reduced precision.
More details of the bfloat16 data type can be found at Intel's site and TensorFlow's documentation.
One of the advantages of using bf16 versus f32 is reduced memory footprint and, hence, increased memory access throughput. Additionally, when executing on hardware that supports Intel DL Boost bfloat16 instructions, bf16 may offer an increase in computational throughput.
Most of the primitives have been updated to support the bf16 data type for source and weights tensors. Destination tensors can be specified to have either the bf16 or f32 data type. The latter is intended for cases in which the output is to be fed to operations that do not support bfloat16 or require better precision.
The main difference between implementing training with the f32 data type and with the bf16 data type is the way the weights updates are treated. With the f32 data type, the weights gradients have the same data type as the weights themselves. This is not necessarily the case with the bf16 data type as oneDNN allows some flexibility here. For example, one could maintain a master copy of all the weights, computing weights gradients in f32 and converting the result to bf16 afterwards.
The CNN bf16 training example shows how to use bf16 to train CNNs.

