Core Programming Guide#
Drivers and Devices#
The API architecture exposes both physical and logical abstraction of the underlying devices capabilities. The device, sub-device and memory are exposed at physical level while command queues, events and synchronization methods are defined as logical entities. All logical entities will be bound to device level physical capabilities.
Device discovery APIs enumerate the accelerators functional features. These APIs provide interface to query information like compute unit count within the device or sub device, available memory and affinity to the compute, user managed cache size and work submission command queues.
Drivers#
A driver object represents a collection of physical devices in the system accessed by the same Level-Zero driver.
The application may query the number of Level-Zero drivers installed on the system, and their respective handles, using zeInitDrivers, NOTE zeDriverGet is deprecated as of v1.10 of the L0 Spec.
zeInitDrivers replaces both zeInit and zeDriverGet as of v1.10 of the L0 Spec to both initialize the driver and query the number of drivers.
Usage of zeInitDrivers and zeDriverGet is mutually exclusive and should not be used together. Usage of them together will result in undefined behavior.
More than one driver may be available in the system. For example, one driver may support two GPUs from one vendor, another driver supports a GPU from a different vendor, and finally a different driver may support an NPU.
Driver objects are read-only, global constructs. i.e. Multiple calls to zeInitDrivers with the same flags will return identical driver handles.
A driver handle is primarily used during device discovery and during creation and management of contexts.
Device#
A device object represents a physical device in the system that supports Level-Zero.
The application may query the number devices supported by a driver, and their respective handles, using zeDeviceGet.
Device objects are read-only, global constructs. i.e. Multiple calls to zeDeviceGet will return identical device handles.
A device handle is primarily used during creation and management of resources that are specific to a device.
The application is responsible for sharing memory and explicit submission and synchronization across multiple devices.
Device may expose sub-devices that allow finer-grained control of physical or logical partitions of a device.
The following diagram illustrates the relationship between the driver, device and other objects described in this document.
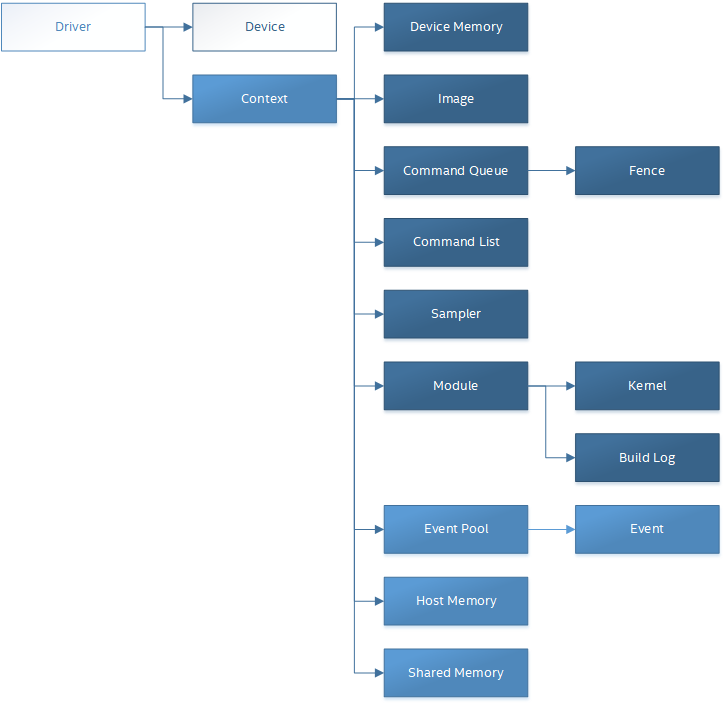
Level Zero device model hierarchy is composed of Root Devices and Sub-Devices: A root-device may contain two or more sub-devices and a sub-device shall belong to a single root-device. A root-device may not contain a single sub-device, as that would be the same root-device. A root device may also be a device with no sub-devices.
Sub-devices belonging to a root-device may be queried using zeDeviceGetSubDevices. The root-device of a sub-device may be queried using zeDeviceGetRootDevice. The definition of what a root-device and a sub-device is for a specific device is implementation specific.
Initialization and Discovery#
The Level-Zero API must be initialized by calling zeInitDrivers before calling any other API function. NOTE: zeInit is deprecated as of v1.10 of the L0 Spec. These functions will load all Level-Zero driver(s) in the system into memory for the current process, for use by all Host threads. Simultaneous calls to zeInitDrivers are thread-safe and only one instance of each driver will be loaded.
The following pseudo-code demonstrates a basic initialization and device discovery sequence for Core Drivers:
// Discover all the driver instances
ze_init_driver_type_desc_t desc = {ZE_STRUCTURE_TYPE_INIT_DRIVER_TYPE_DESC};
desc.pNext = nullptr;
desc.flags = UINT32_MAX; // all driver types requested
uint32_t driverCount = 0;
ze_result_t result = zeInitDrivers(&driverCount, nullptr, &desc); // Query the number of drivers
if (result != ZE_RESULT_SUCCESS) {
return result; // no drivers found
}
ze_driver_handle_t* allDrivers = allocate(driverCount * sizeof(ze_driver_handle_t));
result = zeInitDrivers(&driverCount, allDrivers, &desc); // Read the driver handles
if (result != ZE_RESULT_SUCCESS) {
return result; // no driver handles found
}
// Find a driver Handle that supports a GPU device type
ze_driver_handle_t hDriver = nullptr;
ze_device_handle_t hDevice = nullptr;
for(uint32_t i = 0; i < driverCount; ++i) {
uint32_t deviceCount = 0;
zeDeviceGet(allDrivers[i], &deviceCount, nullptr);
ze_device_handle_t* allDevices = allocate(deviceCount * sizeof(ze_device_handle_t));
zeDeviceGet(allDrivers[i], &deviceCount, allDevices);
for(uint32_t d = 0; d < deviceCount; ++d) {
ze_device_properties_t deviceProperties {};
deviceProperties.stype = ZE_STRUCTURE_TYPE_DEVICE_PROPERTIES_1_2; // ZE_STRUCTURE_TYPE_DEVICE_PROPERTIES deprecated since 1.17
zeDeviceGetProperties(allDevices[d], &deviceProperties);
if(ZE_DEVICE_TYPE_GPU == deviceProperties.type) {
hDriver = allDrivers[i];
hDevice = allDevices[d];
break;
}
}
free(allDevices);
if(nullptr != hDriver) {
break;
}
}
free(allDrivers);
if(nullptr == hDevice)
return; // no GPU devices found
...
Contexts#
A context is a logical object used by the driver for managing all memory, command queues/lists, modules, synchronization objects, etc.
A context handle is primarily used during creation and management of resources that may be used by multiple devices.
For example, memory is not implicitly shared across all devices supported by a driver. However, it is available to be explicitly shared.
The following pseudo-code demonstrates a basic context creation:
// Create context ze_context_desc_t ctxtDesc = { ZE_STRUCTURE_TYPE_CONTEXT_DESC, nullptr, 0 }; zeContextCreate(hDriver, &ctxtDesc, &hContext);
An application may optionally create multiple contexts using zeContextCreate.
The primary usage-model for multiple contexts is isolation of memory and objects for multiple libraries within the same process.
The same context may be used simultaneously on multiple Host threads.
The following pseudo-code demonstrates a basic context creation and activation sequence:
// Create context(s) zeContextCreate(hDriver, &ctxtDesc, &hContextA); zeContextCreate(hDriver, &ctxtDesc, &hContextB); zeMemAllocHost(hContextA, &desc, 80, 0, &ptrA); zeMemAllocHost(hContextB, &desc, 88, 0, &ptrB); memcpy(ptrA, ptrB, 0xe); // ok zeMemGetAllocProperties(hContextA, ptrB, &props, &hDevice); // illegal: Context A has no knowledge of ptrB
If a device was hung or reset, then the context is no longer valid and all APIs will return ZE_RESULT_ERROR_DEVICE_LOST when any object associated with that context is used. All pointers to memory allocations and handles to objects (including other contexts) created on the context will be invalid and should no longer be used. An application can use zeContextGetStatus at any time to check the status of a context.
In order to recover, the context must be destroyed using zeContextDestroy. After the device is reset, the application can create a new context and continue operation. An application must call zeDeviceGetStatus to confirm the device has been reset and update the OS handle attached to the device handle. Otherwise, even after the device has been reset, the call to zeContextCreate will fail.
Memory and Images#
Memory is visible to the upper-level software stack as unified memory with a single virtual address space covering both the Host and a specific device.
For GPUs, the API exposes two levels of the device memory hierarchy:
Local Device Memory: can be managed at the device and/or sub device level.
Device Cache(s):
Last Level Cache (L3) can be controlled through memory allocation APIs.
Low Level Cache (L1) can be controlled through program language intrinsics.
The API allows allocation of buffers and images at device and sub device granularity with full cacheablity hints.
Buffers are transparent memory accessed through virtual address pointers
Images are opaque objects accessed through handles
The memory APIs provide allocation methods to allocate either device, host or shared memory. The APIs enable both implicit and explicit management of the resources by the application or runtimes. The interface also provides query capabilities for all memory objects.
There are two types of allocations:
Memory - linear, unformatted allocations for direct access from both the host and device.
Images - non-linear, formatted allocations for direct access from the device.
Memory#
Linear, unformatted memory allocations are represented as pointers in the host application. A pointer on the Host has the same size as a pointer on the device.
Types#
Three types of allocations are supported. The type of allocation describes the ownership of the allocation:
Host allocations are owned by the host and are intended to be allocated out of system memory.
Host allocations are accessible by the host and one or more devices.
The same pointer to a host allocation may be used on the host and all supported devices; they have address equivalence.
Host allocations are not expected to migrate between system memory and device local memory.
Host allocations trade off wide accessibility and transfer benefits for potentially higher per-access costs, such as over PCI express.
Device allocations are owned by a specific device and are intended to be allocated out of device local memory, if present.
Device allocations generally trade off access limitations for higher performance.
With very few exceptions, device allocations may only be accessed by the specific device that they are allocated on, or copied to another device or Host allocation.
The same pointer to a device allocation may be used on any supported device.
Shared allocations share ownership and are intended to migrate between the host and one or more devices.
Shared allocations are accessible by at least the host and an associated device.
Shared allocations may be accessed by other devices in some cases.
Shared allocations trade off transfer costs for per-access benefits.
The same pointer to a shared allocation may be used on the host and all supported devices.
A Shared System allocation is a sub-class of a Shared allocation,
where the memory is allocated by a system allocator (such as malloc or new) rather than by an allocation API.
Shared system allocations have no associated device; they are inherently cross-device.
Like other shared allocations, shared system allocations are intended to migrate between the host and supported devices,
and the same pointer to a shared system allocation may be used on the host and all supported devices.
In summary:
Name |
Initial Location |
Accessible By |
Migratable To |
||
|---|---|---|---|---|---|
Host |
Host |
Host |
Yes |
Host |
N/A |
Any Device |
Yes (perhaps over PCIe) |
Device |
No |
||
Device |
Specific Device |
Host |
No |
Host |
No |
Specific Device |
Yes |
Device |
N/A |
||
Another Device |
Optional (may require p2p) |
Another Device |
No |
||
Shared |
Host, Specific Device, or Unspecified |
Host |
Yes |
Host |
Yes |
Specific Device |
Yes |
Device |
Yes |
||
Another Device |
Optional (may require p2p) |
Another Device |
Optional |
||
Shared System |
Host |
Host |
Yes |
Host |
Yes |
Device |
Yes |
Device |
Yes |
At a minimum, drivers will assign unique physical pages for each device and shared memory allocation. However, it is undefined behavior for an application to access memory outside of the allocation size requested. The actual page size used for an allocation can be queried from ze_memory_allocation_properties_t.pageSize using zeMemGetAllocProperties. Applications should implement usage-specific allocators from device memory pools (e.g., small and/or fixed-sized allocations, lock-free, etc.).
Furthermore, drivers may oversubscribe some shared allocations. When and how such oversubscription occurs, including which allocations are evicted when the working set changes, are considered implementation details.
Access Capabilities#
Devices may support different access capabilities for each type of allocation. Supported capabilities are:
Host Allocations: Assume a buffer allocated on the host via zeMemAllocHost that is accessed from device hDevice:
ZE_MEMORY_ACCESS_CAP_FLAG_RW: Buffer can be accessed (read from as well as written to) from hDevice as well as from the host.
ZE_MEMORY_ACCESS_CAP_FLAG_ATOMIC: Buffer can be atomically accessed from hDevice. Atomic operations may include relaxed consistency read-modify-write atomics and atomic operations that enforce memory consistency for non-atomic operations.
ZE_MEMORY_ACCESS_CAP_FLAG_CONCURRENT: Buffer can be accessed from hDevice concurrently with another device that also supports concurrent access as well as with the host itself. Concurrent access is at the granularity of the whole allocation. This capability makes no guarantees about coherency or memory consistency. Undefined behavior occurs if concurrent accesses are made to an allocation from devices that do not support concurrent access. Devices that support concurrent access but do not support concurrent atomic access must write to unique non-overlapping memory locations to avoid data races and hence undefined behavior.
ZE_MEMORY_ACCESS_CAP_FLAG_CONCURRENT_ATOMIC: Buffer can be atomically accessed from hDevice concurrently with another device that also supports concurrent atomic access as well as with the host itself. Concurrent atomic access is at the granularity of the whole allocation. Memory consistency can be enforced between the host & devices that support concurrent atomic access using atomic operations. Undefined behavior occurs if concurrent atomic accesses are made to an allocation from devices that do not support concurrent atomic access.
Device Allocations: Assume a buffer allocated on device hDevice via zeMemAllocDevice:
ZE_MEMORY_ACCESS_CAP_FLAG_RW: Buffer can be accessed (read from as well as written to) from hDevice.
ZE_MEMORY_ACCESS_CAP_FLAG_ATOMIC: Buffer can be atomically accessed from hDevice. Atomic operations may include relaxed consistency read-modify-write atomics and atomic operations that enforce memory consistency for non-atomic operations.
ZE_MEMORY_ACCESS_CAP_FLAG_CONCURRENT: Buffer can be accessed from hDevice concurrently with another device that also supports concurrent access. By symmetry, the buffer could be located on either device and be accessed concurrently from both devices. Concurrent access is at the granularity of the whole allocation. This capability makes no guarantees about coherency or memory consistency. Undefined behavior occurs if concurrent accesses are made to an allocation from devices that do not support concurrent access. Devices that support concurrent access but do not support concurrent atomic access must write to unique non-overlapping memory locations to avoid data races and hence undefined behavior. A device can concurrently access a buffer on another device if both devices support concurrent access and both devices also support peer-to-peer access. If one device does not permit concurrent access, but peer-to-peer access is permitted, then the devices support peer-to-peer access but not concurrently to the same buffer.
ZE_MEMORY_ACCESS_CAP_FLAG_CONCURRENT_ATOMIC: Buffer can be atomically accessed from hDevice concurrently with another device that also supports concurrent atomic access. By symmetry, the buffer could be located on either device and be atomically accessed concurrently from both devices. Concurrent atomic access is at the granularity of the whole allocation. Memory consistency can be enforced between devices that support concurrent atomic access using atomic operations. Undefined behavior occurs if concurrent atomic accesses are made to an allocation from devices that do not support concurrent atomic access. A device can concurrently perform atomic access to a device buffer on another device if both devices support concurrent atomic access and both devices also support peer-to-peer atomic access. If one device does not permit concurrent atomic access, but peer-to-peer atomic access is permitted, then the devices support peer-to-peer atomic access but not concurrently to the same buffer.
Shared Single Device Allocations: Assume a shared allocation across the host & device hDevice created via zeMemAllocShared
ZE_MEMORY_ACCESS_CAP_FLAG_RW: Buffer can be accessed (read from as well as written to) from hDevice as well as from the host.
ZE_MEMORY_ACCESS_CAP_FLAG_ATOMIC: Buffer can be atomically accessed from hDevice as well as from the host. Atomic operations may include relaxed consistency read-modify-write atomics and atomic operations that enforce memory consistency for non-atomic operations.
ZE_MEMORY_ACCESS_CAP_FLAG_CONCURRENT: Buffer can be accessed from hDevice concurrently with the host. Concurrent access is at the granularity of the whole allocation. This capability makes no guarantees about coherency or memory consistency. Undefined behavior occurs if concurrent accesses are made to the allocation from the host and from hDevice if it does not support concurrent access. A devices that supports concurrent access but does not support concurrent atomic access must write to unique non-overlapping (with the host) memory locations to avoid data races and hence undefined behavior.
ZE_MEMORY_ACCESS_CAP_FLAG_CONCURRENT_ATOMIC: Buffer can be atomically accessed from hDevice concurrently with the host. Concurrent atomic access is at the granularity of the whole allocation. Memory consistency can be enforced between devices that support concurrent atomic access using atomic operations. Undefined behavior occurs if concurrent atomic accesses are made to the allocation from the host & hDevice if it does not support concurrent atomic access.
Shared Cross Device Allocations: Assume a shared allocation across the host & the set of devices that support cross-device shared access capabilities created via zeMemAllocShared that is accessed from device hDevice:
ZE_MEMORY_ACCESS_CAP_FLAG_RW: Buffer can be accessed (read from as well as written to) from hDevice as well as from the host.
ZE_MEMORY_ACCESS_CAP_FLAG_ATOMIC: Buffer can be atomically accessed from hDevice as well as from the host. Atomic operations may include relaxed consistency read-modify-write atomics and atomic operations that enforce memory consistency for non-atomic operations.
ZE_MEMORY_ACCESS_CAP_FLAG_CONCURRENT: Buffer can be accessed from hDevice concurrently with another device that also supports concurrent access and from the host. Concurrent access is at the granularity of the whole allocation. This capability makes no guarantees about coherency or memory consistency. Undefined behavior occurs if concurrent accesses are made to an allocation from devices that do not support concurrent access. Devices that support concurrent access but do not support concurrent atomic access must write to unique non-overlapping memory locations to avoid data races and hence undefined behavior.
ZE_MEMORY_ACCESS_CAP_FLAG_CONCURRENT_ATOMIC: Buffer can be atomically accessed from hDevice concurrently with another device that also supports concurrent atomic access and from the host. Concurrent atomic access is at the granularity of the whole allocation. Memory consistency can be enforced between devices that support concurrent atomic access using atomic operations. Undefined behavior occurs if concurrent atomic accesses are made to an allocation from devices that do not support concurrent atomic access.
The required matrix of capabilities are:
Allocation Type |
RW Access |
Atomic Access |
Concurrent Access |
Concurrent Atomic Access |
|---|---|---|---|---|
Host |
Required |
Optional |
Optional |
Optional |
Device |
Required |
Optional |
Optional |
Optional |
Shared |
Required |
Optional |
Optional |
Optional |
Shared (Cross-Device) |
Optional |
Optional |
Optional |
Optional |
Shared System (Cross-Device) |
Optional |
Optional |
Optional |
Optional |
Cache Hints, Prefetch, and Memory Advice#
Cacheability hints may be provided via separate host and device allocation flags when memory is allocated.
Shared allocations may be prefetched to a supporting device via the zeCommandListAppendMemoryPrefetch API. Prefetching may allow memory transfers to be scheduled concurrently with other computations and may improve performance.
Additionally, an application may provide memory advice for a shared allocation via the zeCommandListAppendMemAdvise API, to override driver heuristics or migration policies. Memory advice may avoid unnecessary or unprofitable memory transfers and may improve performance.
Both prefetch and memory advice are asynchronous operations that are appended into command lists.
Reserved Device Allocations#
If an application needs finer grained control of physical memory consumption for device allocations then it can reserve a range of the virtual address space and map this to physical memory as needed. This provides flexibility for applications to manage large dynamic data structures which can grow and shrink over time while maintaining optimal physical memory usage.
Reserving Virtual Address Space#
Virtual memory can be reserved using zeVirtualMemReserve. The reservation starting address and size must be page aligned. Applications should query the page size for the allocation using zeVirtualMemQueryPageSize.
The following pseudo-code demonstrates a basic sequence for reserving virtual memory:
// Query page size for our 1MB allocation. size_t pageSize; size_t allocationSize = 1048576; zeVirtualMemQueryPageSize(hContext, hDevice, allocationSize, &pageSize); // Reserve 1MB of virtual address space. size_t reserveSize = align(allocationSize, pageSize); void* ptr = nullptr; zeVirtualMemReserve(hContext, nullptr, reserveSize, &ptr);
Growing Virtual Address Reservations#
An application may wish to reserve an address range starting at a specific virtual address. This may be useful when there is a need to grow a reservation. However, if the implementation is not able to reserve the new allocation at the requested starting address then it will find a new suitable range with a different starting address. If the application requires a specific starting address then the application should ensure that the return address from zeVirtualMemReserve matches the starting address it wants. If they are different then the application may want to create a new larger reservation and remap the physical memory from the first reservation to this new reservation and free the old reservation.
// Reserve another 1MB of virtual address space that is contiguous with previous reservation. void* newptr = (uint8_t*)ptr + reserveSize; void* retptr; zeVirtualMemReserve(hContext, newptr, reserveSize, &retptr); if (retptr != newptr) { // Free new reservation as it's not what we want due to incorrect starting address. zeVirtualMemFree(hContext, retptr, reserveSize); // Make new larger 2MB reservation and remap physical pages to this. size_t pageSize; size_t largerAllocationSize = 2097152; zeVirtualMemQueryPageSize(hContext, hDevice, largerAllocationSize, &pageSize); // Reserve 2MB of virtual address space. size_t largerReserveSize = align(largerAllocationSize, pageSize); void* ptr = nullptr; zeVirtualMemReserve(hContext, nullptr, largerReserveSize, &ptr); // Remap physical pages from original reservation to our new larger reservation. ... // Free original reservation that we were trying to grow. zeVirtualMemFree(hContext, ptr, reserveSize); }
Physical Memory#
Physical memory is explicitly represented in the API as physical memory objects that are reservations of physical pages. The application will use zePhysicalMemCreate to create a physical memory object.
The following pseudo-code demonstrates a basic sequence for creating a physical memory object:
// Create 1MB physical memory object ze_physical_mem_handle_t hPhysicalAlloc; size_t physicalSize = align(allocationSize, pageSize); ze_physical_mem_desc_t pmemDesc = { ZE_STRUCTURE_TYPE_PHYSICAL_MEM_DESC, nullptr, 0, // flags physicalSize // size }; zePhysicalMemCreate(hContext, hDevice, &pmemDesc, &hPhysicalAlloc);
Reading Physical Memory Properties#
An application can query properties of a physical memory object using zePhysicalMemGetProperties.
The following pseudo-code demonstrates querying properties of a physical memory object:
// Set up the request for an exportable allocation
ze_external_memory_export_desc_t export_desc = {
ZE_STRUCTURE_TYPE_EXTERNAL_MEMORY_EXPORT_DESC,
nullptr, // pNext
ZE_EXTERNAL_MEMORY_TYPE_FLAG_OPAQUE_FD
};
ze_physical_mem_desc_t alloc_desc = {
.stype = ZE_STRUCTURE_TYPE_PHYSICAL_MEM_DESC,
.pNext = &export_desc,
.flags = 0,
.size = 1024
};
ze_physical_mem_handle_t hPhysicalMemory;
zePhysicalMemCreate(hContext, hDevice, &alloc_desc, &hPhysicalMemory)
// Set up the request to export the external memory handle
ze_external_memory_export_fd_t export_fd = {
ZE_STRUCTURE_TYPE_EXTERNAL_MEMORY_EXPORT_FD,
nullptr, // pNext
ZE_EXTERNAL_MEMORY_TYPE_FLAG_OPAQUE_FD,
0 // [out] fd
};
// Link the export request into the query
ze_physical_mem_properties_t physicalMemProperties = {
ZE_STRUCTURE_TYPE_PHYSICAL_MEM_PROPERTIES
};
physicalMemProperties.pNext = &export_fd;
zePhysicalMemGetProperties(hContext, hPhysicalMemory, &physicalMemProperties)
// User sends exportFd.fd to a peer process
int imported_fd = /* fd received from peer process */;
// For importing reuse existing structs
ze_external_memory_import_fd_t import_fd = {
.stype = ZE_STRUCTURE_TYPE_EXTERNAL_MEMORY_IMPORT_FD,
.pNext = nullptr,
.flags = ZE_EXTERNAL_MEMORY_TYPE_FLAG_OPAQUE_FD,
.fd = imported_fd
};
ze_physical_mem_desc_t alloc_desc = {
.stype = ZE_STRUCTURE_TYPE_PHYSICAL_MEM_DESC,
.pNext = &import_fd,
.flags = 0,
.size = 1024
};
zePhysicalMemCreate(hContext, hDevice, &alloc_desc, &physicalMemImporter);
External Memory IPC with Physical Memory — Export Without Local Mapping#
An application can share a physical memory object with a peer process using only a file descriptor obtained via zePhysicalMemGetProperties, without the exporting process needing to map the memory itself. The exporting process creates the physical memory object with an export descriptor, retrieves the file descriptor, and passes it to the peer via an OS IPC mechanism (e.g. a Unix domain socket). The importing process then reconstructs the physical memory object and maps it into its own virtual address space.
The following pseudo-code demonstrates export without a local mapping on the exporting side:
// === Exporting process === // Allocate a page-aligned physical memory object with export capability size_t pageSize; size_t allocationSize = 1048576; // 1 MB zeVirtualMemQueryPageSize(hContext, hDevice, allocationSize, &pageSize); size_t physicalSize = align(allocationSize, pageSize); ze_external_memory_export_desc_t exportDesc = { ZE_STRUCTURE_TYPE_EXTERNAL_MEMORY_EXPORT_DESC, nullptr, ZE_EXTERNAL_MEMORY_TYPE_FLAG_OPAQUE_FD }; ze_physical_mem_desc_t physMemDesc = { ZE_STRUCTURE_TYPE_PHYSICAL_MEM_DESC, &exportDesc, // pNext chains the export request 0, // flags physicalSize }; ze_physical_mem_handle_t hPhysicalMemory; zePhysicalMemCreate(hContext, hDevice, &physMemDesc, &hPhysicalMemory); // Query properties to retrieve the exportable file descriptor ze_external_memory_export_fd_t exportFd = { ZE_STRUCTURE_TYPE_EXTERNAL_MEMORY_EXPORT_FD, nullptr, ZE_EXTERNAL_MEMORY_TYPE_FLAG_OPAQUE_FD, 0 // [out] fd populated by the driver }; ze_physical_mem_properties_t physMemProps = { ZE_STRUCTURE_TYPE_PHYSICAL_MEM_PROPERTIES, &exportFd }; zePhysicalMemGetProperties(hContext, hPhysicalMemory, &physMemProps); // exportFd.fd now holds a valid OS file descriptor // Transfer exportFd.fd to the peer process via an OS IPC mechanism // (e.g. Unix domain socket). No local VA mapping is required on this side. // === Importing process === // Reconstruct the physical memory object from the received file descriptor int imported_fd = /* fd received from the exporting process */; ze_external_memory_import_fd_t importFd = { ZE_STRUCTURE_TYPE_EXTERNAL_MEMORY_IMPORT_FD, nullptr, ZE_EXTERNAL_MEMORY_TYPE_FLAG_OPAQUE_FD, imported_fd }; ze_physical_mem_desc_t importMemDesc = { ZE_STRUCTURE_TYPE_PHYSICAL_MEM_DESC, &importFd, // pNext chains the import request 0, // flags physicalSize }; ze_physical_mem_handle_t hPhysicalMemoryImport; zePhysicalMemCreate(hContext, hDevice, &importMemDesc, &hPhysicalMemoryImport); // Map the imported physical memory into this process's virtual address space void* importPtr = nullptr; zeVirtualMemReserve(hContext, nullptr, physicalSize, &importPtr); zeVirtualMemMap(hContext, importPtr, physicalSize, hPhysicalMemoryImport, 0, ZE_MEMORY_ACCESS_ATTRIBUTE_READWRITE); // The importing process can now access the shared physical pages via importPtr.
External Memory IPC with Physical Memory — Export With Local Mapping#
Alternatively, the exporting process may also map the physical memory into its own virtual address space before sharing the file descriptor. This allows both the exporting and importing processes to access the same underlying physical pages concurrently via their respective virtual address mappings.
The following pseudo-code demonstrates export with an optional local mapping on the exporting side:
// === Exporting process === // Allocate a page-aligned physical memory object with export capability size_t pageSize; size_t allocationSize = 1048576; // 1 MB zeVirtualMemQueryPageSize(hContext, hDevice, allocationSize, &pageSize); size_t physicalSize = align(allocationSize, pageSize); ze_external_memory_export_desc_t exportDesc = { ZE_STRUCTURE_TYPE_EXTERNAL_MEMORY_EXPORT_DESC, nullptr, ZE_EXTERNAL_MEMORY_TYPE_FLAG_OPAQUE_FD }; ze_physical_mem_desc_t physMemDesc = { ZE_STRUCTURE_TYPE_PHYSICAL_MEM_DESC, &exportDesc, // pNext chains the export request 0, // flags physicalSize }; ze_physical_mem_handle_t hPhysicalMemory; zePhysicalMemCreate(hContext, hDevice, &physMemDesc, &hPhysicalMemory); // Query properties to retrieve the exportable file descriptor ze_external_memory_export_fd_t exportFd = { ZE_STRUCTURE_TYPE_EXTERNAL_MEMORY_EXPORT_FD, nullptr, ZE_EXTERNAL_MEMORY_TYPE_FLAG_OPAQUE_FD, 0 // [out] fd populated by the driver }; ze_physical_mem_properties_t physMemProps = { ZE_STRUCTURE_TYPE_PHYSICAL_MEM_PROPERTIES, &exportFd }; zePhysicalMemGetProperties(hContext, hPhysicalMemory, &physMemProps); // exportFd.fd now holds a valid OS file descriptor // Optionally map the physical memory into the exporting process's VA space void* exportPtr = nullptr; zeVirtualMemReserve(hContext, nullptr, physicalSize, &exportPtr); zeVirtualMemMap(hContext, exportPtr, physicalSize, hPhysicalMemory, 0, ZE_MEMORY_ACCESS_ATTRIBUTE_READWRITE); // Transfer exportFd.fd to the peer process via an OS IPC mechanism // (e.g. Unix domain socket). The receiving side gets imported_fd. // === Importing process === // Reconstruct the physical memory object from the received file descriptor int imported_fd = /* fd received from the exporting process */; ze_external_memory_import_fd_t importFd = { ZE_STRUCTURE_TYPE_EXTERNAL_MEMORY_IMPORT_FD, nullptr, ZE_EXTERNAL_MEMORY_TYPE_FLAG_OPAQUE_FD, imported_fd }; ze_physical_mem_desc_t importMemDesc = { ZE_STRUCTURE_TYPE_PHYSICAL_MEM_DESC, &importFd, // pNext chains the import request 0, // flags physicalSize }; ze_physical_mem_handle_t hPhysicalMemoryImport; zePhysicalMemCreate(hContext, hDevice, &importMemDesc, &hPhysicalMemoryImport); // Map the imported physical memory into this process's virtual address space void* importPtr = nullptr; zeVirtualMemReserve(hContext, nullptr, physicalSize, &importPtr); zeVirtualMemMap(hContext, importPtr, physicalSize, hPhysicalMemoryImport, 0, ZE_MEMORY_ACCESS_ATTRIBUTE_READWRITE); // Both processes now access the same underlying physical pages via their // respective virtual address mappings (exportPtr and importPtr).
Mapping Virtual Memory Pages#
Reserved virtual memory pages can be mapped to physical memory using zeVirtualMemMap. An application can map the entire reserved virtual address range or can sparsely map the reserved virtual address range using one or more physical memory objects. Once mapped, the physical pages for a physical memory object can be faulted in for devices that support on-demand paging. In addition, the residency API can be used to control residency of these physical pages.
The following pseudo-code demonstrates mapping a 1MB reservation into physical memory:
// Map entire 1MB reservation and set access to read/write. zeVirtualMemMap(hContext, ptr, reserveSize, hPhysicalAlloc, 0, ZE_MEMORY_ACCESS_ATTRIBUTE_READWRITE);
Access Attributes#
Access attributes can be set for a range of pages when mapping virtual memory pages with zeVirtualMemMap or with zeVirtualMemSetAccessAttribute. In addition, an application can query access attributes for a page aligned virtual memory range.
size_t accessRangeSize; ze_memory_access_attribute_t access; zeVirtualMemGetAccessAttribute(hContext, ptr, reserveSize, &access, &accessRangeSize); // Expecting entire range to have the same access attribute and it be read/write. assert(accessRangeSize == reserveSize); assert(access == ZE_MEMORY_ACCESS_ATTRIBUTE_READWRITE);
Sparse Mappings#
Applications may desire to reserve large virtual address ranges to make available to its custom allocators. These ranges can be sparsely mapped using one or more physical memory objects. It is recommended that the application queries the page size for each suballocation to ensure the implementation can use an optimal page size for the mappings based on the alignments used for starting address and size used.
The following example makes a 1GB reserved allocation and then makes both 128KB and 8MB sub-allocations.
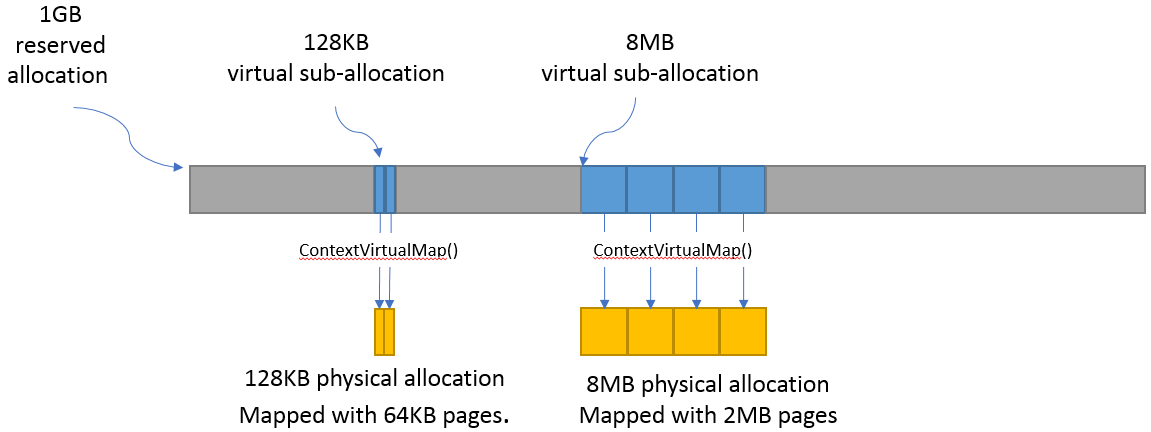
// Reserve 1GB of virtual address space to manage. size_t pageSize; size_t allocationSize = 1048576000; zeVirtualMemQueryPageSize(hContext, hDevice, allocationSize, &pageSize); size_t reserveSize = align(allocationSize, pageSize); void* ptr = nullptr; zeVirtualMemReserve(hContext, nullptr, reserveSize, &ptr); ... // Sub-allocate 128KB of our 1GB allocation. size_t subAllocSize = 131072; zeVirtualMemQueryPageSize(hContext, hDevice, subAllocSize, &pageSize); // Create physical memory object for our 128KB sub-allocation. size_t subAllocAlignedSize = align(subAllocSize, pageSize); ze_physical_mem_desc_t pmemDesc = { ZE_STRUCTURE_TYPE_PHYSICAL_MEM_DESC, nullptr, 0, // flags subAllocAlignedSize // size }; ze_physical_mem_handle_t hPhysicalAlloc; zePhysicalMemCreate(hContext, hDevice, &pmemDesc, &hPhysicalAlloc); // Find suitable 128KB sub-allocation that matches page alignments. ... zeVirtualMemMap(hContext, subAllocPtr, subAllocAlignedSize, hPhysicalAlloc, 0, ZE_MEMORY_ACCESS_ATTRIBUTE_READWRITE); ... // Sub-allocate 8MB of our 1GB allocation. size_t subAllocDiffSize = 8388608; zeVirtualMemQueryPageSize(hContext, hDevice, subAllocDiffSize, &pageSize); ...
Images#
An image is used to store multi-dimensional and format-defined memory. An image’s contents may be stored in an implementation-specific encoding and layout in memory for optimal device access (e.g., tile swizzle patterns, lossless compression, etc.). There is no support for direct Host access to an image’s content. However, when an image is copied to a Host-accessible memory allocation, its contents will be implicitly decoded to be implementation-independent.
// Specify single component FLOAT32 format ze_image_format_t format = { ZE_IMAGE_FORMAT_LAYOUT_32, ZE_IMAGE_FORMAT_TYPE_FLOAT, ZE_IMAGE_FORMAT_SWIZZLE_R, ZE_IMAGE_FORMAT_SWIZZLE_0, ZE_IMAGE_FORMAT_SWIZZLE_0, ZE_IMAGE_FORMAT_SWIZZLE_1 }; ze_image_desc_t imageDesc = { ZE_STRUCTURE_TYPE_IMAGE_DESC, nullptr, 0, // read-only ZE_IMAGE_TYPE_2D, format, 128, 128, 0, 0, 0 }; ze_image_handle_t hImage; zeImageCreate(hContext, hDevice, &imageDesc, &hImage); // upload contents from host pointer zeCommandListAppendImageCopyFromMemory(hCommandList, hImage, nullptr, pImageData, nullptr, 0, nullptr); ...
A format descriptor is a combination of a format layout, type, and a swizzle. The format layout describes the number of components and their corresponding bit widths. The type describes the data type for all of these components with some exceptions that are described below. The swizzles associate how the image components are mapped into XYZW/RGBA channels of the kernel. It is allowed to replicate components into the channels.
The following table describes which types are required for each layout.
Format layout |
UINT |
SINT |
UNORM |
SNORM |
FLOAT |
|---|---|---|---|---|---|
8 |
Required |
Required |
Required |
Required |
Unsupported |
8_8 |
Required |
Required |
Required |
Required |
Unsupported |
8_8_8_8 |
Required |
Required |
Required |
Required |
Unsupported |
16 |
Required |
Required |
Required |
Required |
Required |
16_16 |
Required |
Required |
Required |
Required |
Required |
16_16_16_16 |
Required |
Required |
Required |
Required |
Required |
32 |
Required |
Required |
Required |
Required |
Required |
32_32 |
Required |
Required |
Required |
Required |
Required |
32_32_32_32 |
Required |
Required |
Required |
Required |
Required |
10_10_10_2 |
Required |
Required |
Required |
Required |
Required |
11_11_10 |
Unsupported |
Unsupported |
Unsupported |
Unsupported |
Required |
5_6_5 |
Unsupported |
Unsupported |
Required |
Unsupported |
Unsupported |
5_5_5_1 |
Unsupported |
Unsupported |
Required |
Unsupported |
Unsupported |
4_4_4_4 |
Unsupported |
Unsupported |
Required |
Unsupported |
Unsupported |
Device Cache Settings#
There are two methods for device and kernel cache control:
Cache Size Configuration: Ability to configure larger size for SLM vs Data per Kernel instance.
Runtime Hint/preference for application to allow access to be Cached or not in Device Caches. For GPU device this is provided via two ways:
During Image creation via Flag
Kernel instruction
The following pseudo-code demonstrates a basic sequence for Cache size configuration:
// Configure cache to support larger SLM // Note: The cache setting is applied to each kernel. zeKernelSetCacheConfig(hKernel, ZE_CACHE_CONFIG_FLAG_LARGE_SLM);
External Memory Import and Export#
External memory handles may be imported from other APIs, or exported for use in other APIs. Importing and exporting external memory is an optional feature. Devices may describe the types of external memory handles they support using zeDeviceGetExternalMemoryProperties.
Importing and exporting external memory is supported for device and host memory allocations and images.
The following pseudo-code demonstrates how to allocate and export an external memory handle for a device memory allocation as a Linux dma_buf:
// Set up the request for an exportable allocation ze_external_memory_export_desc_t export_desc = { ZE_STRUCTURE_TYPE_EXTERNAL_MEMORY_EXPORT_DESC, nullptr, // pNext ZE_EXTERNAL_MEMORY_TYPE_FLAG_DMA_BUF }; // Link the request into the allocation descriptor and allocate alloc_desc.pNext = &export_desc; zeMemAllocDevice(hContext, &alloc_desc, size, alignment, hDevice, &ptr); ... // Set up the request to export the external memory handle ze_external_memory_export_fd_t export_fd = { ZE_STRUCTURE_TYPE_EXTERNAL_MEMORY_EXPORT_FD, nullptr, // pNext ZE_EXTERNAL_MEMORY_TYPE_FLAG_OPAQUE_FD, 0 // [out] fd }; // Link the export request into the query alloc_props.pNext = &export_fd; zeMemGetAllocProperties(hContext, ptr, &alloc_props, nullptr);
The following pseudo-code demonstrates how to import a Linux dma_buf as an external memory handle for a device memory allocation:
// Set up the request to import the external memory handle ze_external_memory_import_fd_t import_fd = { ZE_STRUCTURE_TYPE_EXTERNAL_MEMORY_IMPORT_FD, nullptr, // pNext ZE_EXTERNAL_MEMORY_TYPE_FLAG_DMA_BUF, fd }; // Link the request into the allocation descriptor and allocate alloc_desc.pNext = &import_fd; zeMemAllocDevice(hContext, &alloc_desc, size, alignment, hDevice, &ptr);
The following pseudo-code demonstrates how to import a Linux dma_buf as an external memory handle for Images:
// Set up the request to import the external memory handle ze_external_memory_import_fd_t import_fd = { ZE_STRUCTURE_TYPE_EXTERNAL_MEMORY_IMPORT_FD, nullptr, // pNext ZE_EXTERNAL_MEMORY_TYPE_FLAG_DMA_BUF, fd }; // Link the request into the allocation descriptor and allocate image_desc.pNext = &import_fd; // extend ze_image_desc_t // Setup matching image properties for imported image. image_desc.width = import_width; ... zeImageCreate(hContext, hDevice, &image_desc, &hImage);
The following pseudo-code demonstrates how to import a Linux dma_buf as an external memory handle for Physical Memory:
// Set up the request to import the external memory handle ze_external_memory_import_fd_t import_fd = { ZE_STRUCTURE_TYPE_EXTERNAL_MEMORY_IMPORT_FD, nullptr, // pNext ZE_EXTERNAL_MEMORY_TYPE_FLAG_DMA_BUF, fd }; ze_physical_mem_desc_t allocDesc = { .stype = ZE_STRUCTURE_TYPE_PHYSICAL_MEM_DESC, .pNext = &import_fd, .flags = 0, .size = 1024 }; zePhysicalMemCreate(hContext, hDevice, &allocDesc, &physicalMemImporter);
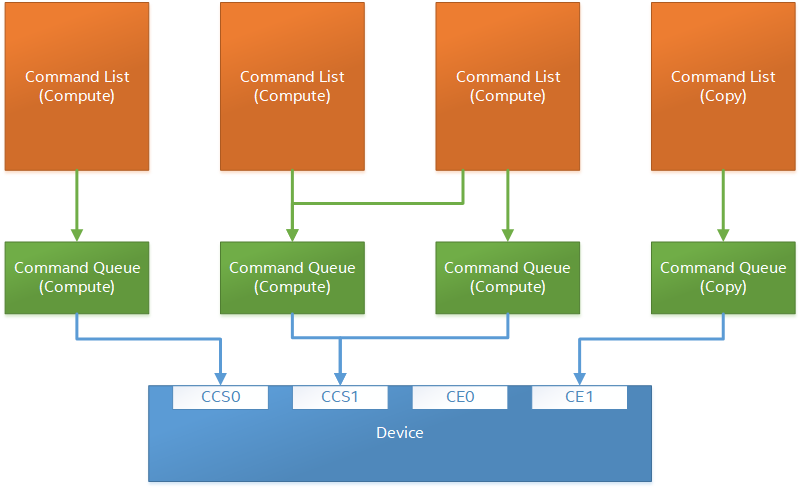
Command Queues and Command Lists#
The following are the motivations for separating a command queue from a command list:
Command queues are mostly associated with physical device properties, such as the number of input streams.
Command queues provide (near) zero-latency access to the device.
Command lists are mostly associated with Host threads for simultaneous construction.
Command list construction can occur independently of command queue submission.
The following diagram illustrates the hierarchy of command lists and command queues to the device:
Command Queue Groups#
A command queue group represents a physical input stream, which represents one or more physical device engines.
Discovery#
The number and properties of command queue groups is queried by using zeDeviceGetCommandQueueGroupProperties.
The number of physical engines within a group is queried from ze_command_queue_group_properties_t.numQueues.
The types of commands supported by the group is queried from ze_command_queue_group_properties_t.flags.
For example, if a command list is meant to be submitted to a copy-only engine, then it must be created using a command queue group ordinal with ZE_COMMAND_QUEUE_GROUP_PROPERTY_FLAG_COPY set and ZE_COMMAND_QUEUE_GROUP_PROPERTY_FLAG_COMPUTE not set, and submitted to a command queue created using the same ordinal.
The following pseudo-code demonstrates a basic sequence for discovery of command queue groups:
// Discover all command queue groups uint32_t cmdqueueGroupCount = 0; zeDeviceGetCommandQueueGroupProperties(hDevice, &cmdqueueGroupCount, nullptr); ze_command_queue_group_properties_t* cmdqueueGroupProperties = (ze_command_queue_group_properties_t*) allocate(cmdqueueGroupCount * sizeof(ze_command_queue_group_properties_t)); cmdqueueGroupProperties[ i ].stype = ZE_STRUCTURE_TYPE_COMMAND_QUEUE_GROUP_PROPERTIES; cmdqueueGroupProperties[ i ].pNext = nullptr; zeDeviceGetCommandQueueGroupProperties(hDevice, &cmdqueueGroupCount, cmdqueueGroupProperties); // Find a command queue type that support compute uint32_t computeQueueGroupOrdinal = cmdqueueGroupCount; for( uint32_t i = 0; i < cmdqueueGroupCount; ++i ) { if( cmdqueueGroupProperties[ i ].flags & ZE_COMMAND_QUEUE_GROUP_PROPERTY_FLAG_COMPUTE ) { computeQueueGroupOrdinal = i; break; } } if(computeQueueGroupOrdinal == cmdqueueGroupCount) return; // no compute queues found
Command Queues#
A command queue represents a logical input stream to the device, tied to a physical input stream.
Creation#
At creation time, the command queue is explicitly bound to a command queue group via its ordinal.
Multiple command queues may be created that use the same command queue group. For example, an application may create a command queue per Host thread with different scheduling priorities.
Multiple command queues created for the same command queue group on the same context, may also share the same physical hardware context.
The maximum number of command queues an application can create is limited by device-specific resources; e.g., the maximum number of logical hardware contexts supported by the device. This can be queried from ze_device_properties_t.maxHardwareContexts.
The physical engine within a command queue group on which a command queue executes is virtualized via its index, limited by the number of physical engines of the type of the command queue group, i.e. ze_command_queue_group_properties_t.numQueues.
The command queue index provides a mechanism for an application to indicate which command queues can execute concurrently (different indices).
Command queues that do not share the same index may launch and execute concurrently.
Command queues that share the same index launch sequentially but may execute concurrently.
All command lists executed on a command queue are guaranteed to only execute on an engine from the command queue group to which it is assigned; e.g., copy commands in a compute command list / queue will execute via the compute engine, not the copy engine.
There is no guarantee that command lists submitted to command queues with different indices will execute concurrently, only a possibility that they might execute concurrently.
The following pseudo-code demonstrates a basic sequence for creation of command queues:
// Create a command queue ze_command_queue_desc_t commandQueueDesc = { ZE_STRUCTURE_TYPE_COMMAND_QUEUE_DESC, nullptr, computeQueueGroupOrdinal, 0, // index 0, // flags ZE_COMMAND_QUEUE_MODE_DEFAULT, ZE_COMMAND_QUEUE_PRIORITY_NORMAL }; ze_command_queue_handle_t hCommandQueue; zeCommandQueueCreate(hContext, hDevice, &commandQueueDesc, &hCommandQueue); ...
Execution#
Command lists submitted to a command queue are immediately submitted to the device for execution.
Submitting multiple commands lists in a single submission allows an implementation the opportunity to optimize across command lists.
Command queue submission is free-threaded, allowing multiple Host threads to share the same command queue.
If multiple Host threads enter the same command queue simultaneously, then execution order is undefined.
Command lists can only be executed on a command queue with an identical command queue group ordinal.
Destruction#
The application is responsible for making sure the device is not currently executing from a command queue before it is deleted. This is typically done by tracking command queue fences, but may also be handled by calling zeCommandQueueSynchronize.
Command Lists#
A command list represents a sequence of commands for execution on a command queue.
Creation#
A command list is created for a device to allow device-specific appending of commands.
A command list is created for execution on a specific type of command queue, specified using the command queue group ordinal.
A command list can be copied to create another command list. The application may use this to copy a command list for use on a different device.
Appending#
There is no implicit binding of command lists to Host threads. Therefore, an application may share a command list handle across multiple Host threads. However, the application is responsible for ensuring that multiple Host threads do not access the same command list simultaneously.
By default, commands are started in the same order in which they are appended. However, an application may allow the driver to optimize the ordering by using ZE_COMMAND_LIST_FLAG_RELAXED_ORDERING. Reordering is guaranteed to only occur between barriers and synchronization primitives.
By default, commands submitted to a command list are optimized for execution by balancing both device throughput and Host latency.
For very low-level latency usage-models, applications should use immediate command lists.
For usage-models where maximum throughput is desired, applications should use ZE_COMMAND_LIST_FLAG_MAXIMIZE_THROUGHPUT. This flag will indicate to the driver it may perform additional device-specific optimizations.
The following pseudo-code demonstrates a basic sequence for creation of command lists:
// Create a command list ze_command_list_desc_t commandListDesc = { ZE_STRUCTURE_TYPE_COMMAND_LIST_DESC, nullptr, computeQueueGroupOrdinal, 0 // flags }; ze_command_list_handle_t hCommandList; zeCommandListCreate(hContext, hDevice, &commandListDesc, &hCommandList); ...
Submission#
There is no implicit association between a command list and a command queue. Therefore, a command list may be submitted to any or multiple command queues.
By definition, a command list cannot be executed concurrently on multiple command queues.
The application is responsible for calling close before submission to a command queue.
Command lists do not inherit state from other command lists executed on the same command queue. i.e. each command list begins execution in its own default state.
A command list may be submitted multiple times. It is up to the application to ensure that the command list can be executed multiple times. For example, events must be explicitly reset prior to re-execution.
The following pseudo-code demonstrates submission of commands to a command queue, via a command list:
... // finished appending commands (typically done on another thread) zeCommandListClose(hCommandList); // Execute command list in command queue zeCommandQueueExecuteCommandLists(hCommandQueue, 1, &hCommandList, nullptr); // synchronize host and device zeCommandQueueSynchronize(hCommandQueue, UINT32_MAX); // Reset (recycle) command list for new commands zeCommandListReset(hCommandList); ...
Recycling#
A command list may be recycled to avoid the overhead of frequent creation and destruction.
The application is responsible for making sure the device is not currently executing from a command list before it is reset. This should be handled by tracking a completion event associated with the command list.
The application is responsible for making sure the device is not currently executing from a command list before it is deleted. This should be handled by tracking a completion event associated with the command list.
Low-Latency Immediate Command Lists#
A special type of command list can be used for very low-latency submission usage-models.
An immediate command list is both a command list and an implicit command queue.
An immediate command list is created using a command queue descriptor.
Commands appended into an immediate command list are immediately executed on the device.
Commands appended into an immediate command list may execute synchronously, by blocking until the command is complete.
An immediate command list is not required to be closed or reset. However, usage will be honored, and expected behaviors will be followed.
The following pseudo-code demonstrates a basic sequence for creation and usage of immediate command lists:
// Create an immediate command list ze_command_queue_desc_t commandQueueDesc = { ZE_STRUCTURE_TYPE_COMMAND_QUEUE_DESC, nullptr, computeQueueGroupOrdinal, 0, // index 0, // flags ZE_COMMAND_QUEUE_MODE_DEFAULT, ZE_COMMAND_QUEUE_PRIORITY_NORMAL }; ze_command_list_handle_t hCommandList; zeCommandListCreateImmediate(hContext, hDevice, &commandQueueDesc, &hCommandList); // Immediately submit a kernel to the device zeCommandListAppendLaunchKernel(hCommandList, hKernel, &launchArgs, nullptr, 0, nullptr); ...
Appending kernels with additional parameters#
New function is added to pass extra parameters when appending the kernel.
New parameters can be passed from extension and be vendor specific.
This function will allow to pass cooperative kernel using dedicated descriptor.
Multiple additional parameters can be passed as a linked list of descriptors.
If additional parameter or any combination is not supported, driver can return an error.
The following pseudo-code demonstrates appending both regular and cooperative kernels
// existing command list ze_command_list_handle_t hCommandList; // When appending regular kernel, just pass null pointer to extension argument void *pNext = nullptr; zeCommandListAppendLaunchKernelWithParameters(hCommandList, hKernel, &launchArgs, pNext, nullptr, 0, nullptr); // When appending cooperative kernel create cooperative descriptor ze_command_list_append_launch_kernel_param_cooperative_desc_t cooperativeDesc = { ZE_STRUCTURE_TYPE_COMMAND_LIST_APPEND_PARAM_COOPERATIVE_DESC, nullptr, true }; void *pNext = &cooperativeDesc; zeCommandListAppendLaunchKernelWithParameters(hCommandList, hKernel, &launchArgs, pNext, nullptr, 0, nullptr); ...
Appending kernels with arguments#
New function is added to pass group size, arguments and additional extensions when appending the kernel.
Kernel object state is updated with new work group size and new arguments, as if separate zeKernelSetGroupSize and zeKernelSetArgumentValue functions were called.
Kernel arguments are passed as a pointer list where each argument represents a pointer to the argument value on specific index.
All kernel arguments must be provided.
If argument is SLM (size), then SLM size in bytes for this resource is provided under pointer on specific index and its type is size_t.
If argument is an immediate type (i.e. structure, non pointer type), then values under pointer must contain full size of immediate type.
Additional extensions can be passed from extension and be vendor specific.
Multiple additional extensions can be passed as a linked list of descriptors.
If additional extension or any combination is not supported, driver must return an error.
The following pseudo-code demonstrates appending kernel with pointer, SLM and immediate type arguments
// kernel signature
__kernel void foo(__global unsigned int *dstBuff, __local unsigned int *localArray, unsigned int addValue);
// existing command list
ze_command_list_handle_t hCommandList;
// existing kernel
ze_command_list_handle_t hKernel;
// output buffer
void *dstBuff;
// SLM sizes for array
size_t localArraySizeInBytes;
// immediate arg
unsigned int addValue;
void *args[] = { &dstBuff, &localArraySizeInBytes, &addValue};
ze_group_count_t groupCounts = {1,2,3};
ze_group_size_t groupSizes = {1,2,3};
zeCommandListAppendLaunchKernelWithArguments(hCommandList, hKernel, groupCounts, groupSizes, args, nullptr, nullptr, 0, nullptr);
...
Appending Host Functions#
Host functions enable inserting host-side function calls into a command list. When the device reaches a host function entry during command list execution, it invokes the specified callback on the host before proceeding with subsequent commands. The runtime invokes the callback on the host asynchronously with respect to API calls.
Note
The host function callback must match the pfnHostFunction parameter type accepted by zeCommandListAppendHostFunction.
The host function must not call any Level Zero API functions.
The host function may access USM shared and USM host allocations.
In contrast to event-based synchronization - where the application must call zeEventHostSynchronize and block its own thread until the device reaches that point - a host function lets the runtime invoke the host-side work asynchronously, without blocking any application thread.
The following example demonstrates a simplified producer-consumer pattern using an in-order immediate command list for image processing. A kernel processes each frame on the GPU, and a host function notifies a consumer thread that the frame is ready. The consumer thread can begin displaying or saving the frame while the GPU is already processing the next one:
// Host function - signals consumer thread
void ZE_CALLBACK_CONV onFrameReady(void* pUserData)
{
FrameContext* frame = static_cast<FrameContext*>(pUserData);
frame->ready = true;
signalConsumer(frame);
}
// ...
// Create in-order immediate command list
// Create consumer thread that waits for frames
for (int i = 0; i < nFrames; i++) {
// GPU processes frame i
zeCommandListAppendLaunchKernel(hImmCmdList, hKernel, &launchArgs[i], nullptr, 0, nullptr);
// Host function notifies consumer thread that frame i is ready
zeCommandListAppendHostFunction(hImmCmdList, onFrameReady, &frames[i], nullptr, nullptr, 0, nullptr);
}
// Wait for all GPU work to complete
zeCommandListHostSynchronize(hImmCmdList, UINT64_MAX);
Synchronization Primitives#
There are two types of synchronization primitives:
Fences - used to communicate to the host that command queue execution has completed.
Events - used as fine-grain host-to-device, device-to-host or device-to-device execution and memory dependencies.
The following are the motivations for separating the different types of synchronization primitives:
Allows device-specific optimizations for certain types of primitives:
Fences may share device memory with all other fences within the same command queue.
Events may be implemented using pipelined operations as part of the program execution.
Fences are implicit, coarse-grain execution and memory barriers.
Events optionally cause fine-grain execution and memory barriers.
Allows distinction on which type of primitive may be shared across devices.
Generally. Events are generic synchronization primitives that can be used across many different usage-models, including those of fences. However, this generality comes with some cost in memory overhead and efficiency.
Fences#
A fence is a heavyweight synchronization primitive used to communicate to the host that command list execution has completed.
A fence is associated with a single command queue.
A fence can only be signaled from a device’s command queue (e.g. between execution of command lists) and can only be waited upon from the host.
A fence guarantees both execution completion and memory coherency, across the device and host, prior to being signaled.
A fence only has two states: not signaled and signaled.
A fence doesn’t implicitly reset. Signaling a signaled fence (or resetting an unsignaled fence) is valid and has no effect on the state of the fence.
A fence can only be reset from the Host.
A fence cannot be shared across processes.
The following pseudo-code demonstrates a sequence for creation, submission and querying of a fence:
// Create fence ze_fence_desc_t fenceDesc = { ZE_STRUCTURE_TYPE_FENCE_DESC, nullptr, 0 // flags }; ze_fence_handle_t hFence; zeFenceCreate(hCommandQueue, &fenceDesc, &hFence); // Execute a command list with a signal of the fence zeCommandQueueExecuteCommandLists(hCommandQueue, 1, &hCommandList, hFence); // Wait for fence to be signaled zeFenceHostSynchronize(hFence, UINT32_MAX); zeFenceReset(hFence); ...
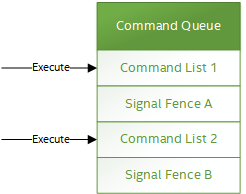
The primary usage model for fences is to notify the Host when a command list has finished execution to allow:
Recycling of memory and images
Recycling of command lists
Recycling of other synchronization primitives
Explicit memory residency.
The following diagram illustrates fences signaled after command lists on execution:
Events#
An event is used to communicate fine-grain host-to-device, device-to-host or device-to-device dependencies have completed.
An event can be:
Signaled from within a device’s command list and waited upon within the same command list
Signaled from within a device’s command list and waited upon from the host, another command queue or another device
Signaled from the host, and waited upon from within a device’s command list.
An event only has two states: not signaled and signaled.
An event doesn’t implicitly reset. Signaling a signaled event (or resetting an unsignaled event) is valid and has no effect on the state of the event.
An event can be explicitly reset from the Host or device.
An event can be appended into multiple command lists simultaneously.
An event can be shared across devices and processes.
An event can invoke an execution and/or memory barrier; which should be used sparingly to avoid device underutilization.
There are no protections against events causing deadlocks, such as circular waits scenarios.
These problems are left to the application to avoid.
An event intended to be signaled by the host, another command queue or another device after command list submission to a command queue may prevent subsequent forward progress within the command queue itself.
This can create bubbles in the pipeline or deadlock situations if not correctly scheduled.
An event pool is used for creation of individual events:
An event pool reduces the cost of creating multiple events by allowing underlying device allocations to be shared by events with the same properties
An event pool can be shared via Inter-Process Communication; allowing sharing blocks of events rather than sharing each individual event
The following pseudo-code demonstrates a sequence for creation and submission of an event:
// Create event pool ze_event_pool_desc_t eventPoolDesc = { ZE_STRUCTURE_TYPE_EVENT_POOL_DESC, nullptr, ZE_EVENT_POOL_FLAG_HOST_VISIBLE, // all events in pool are visible to Host 1 // count }; ze_event_pool_handle_t hEventPool; zeEventPoolCreate(hContext, &eventPoolDesc, 0, nullptr, &hEventPool); ze_event_desc_t eventDesc = { ZE_STRUCTURE_TYPE_EVENT_DESC, nullptr, 0, // index 0, // no additional memory/cache coherency required on signal ZE_EVENT_SCOPE_FLAG_HOST // ensure memory coherency across device and Host after event completes }; ze_event_handle_t hEvent; zeEventCreate(hEventPool, &eventDesc, &hEvent); // Append a signal of an event into the command list after the kernel executes zeCommandListAppendLaunchKernel(hCommandList, hKernel1, &launchArgs, hEvent, 0, nullptr); // Execute the command list with the signal zeCommandQueueExecuteCommandLists(hCommandQueue, 1, &hCommandList, nullptr); // Wait on event to complete zeEventHostSynchronize(hEvent, 0); ...
The following diagram illustrates a dependency between command lists using events:
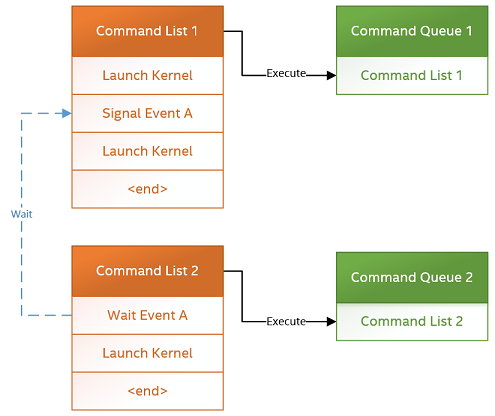
Kernel Timestamp Events#
A kernel timestamp event is a special type of event that records device timestamps at the start and end of the execution of kernels. The primary motivation for kernel timestamps is to provide a duration of execution. For consistency and orthogonality, kernel timestamps are also supported for non-kernel operations. Kernel timestamps execute along a device timeline but because of limited range may wrap unexpectedly. Because of this, the temporal order of two kernel timestamps shouldn’t be inferred despite coincidental START/END values. Timestamps from zeCommandListAppendWriteGlobalTimestamp and kernel timestamp events should not be inferred as equivalent even if reported within identical ranges. timestampValidBits and kernelTimestampValidBits members of ze_device_properties_t, must be used to determine the maximum value of the respective timestamps to detect roll over.
The duration of a kernel timestamp for zeCommandListAppendSignalEvent and zeEventHostSignal is undefined. However, for consistency and orthogonality the event will report correctly as signaled when used by other event API functionality.
A kernel timestamp event result can be queried using either zeEventQueryKernelTimestamp or zeCommandListAppendQueryKernelTimestamps
The ze_kernel_timestamp_result_t contains both the per-context and global timestamp values at the start and end of the kernel’s execution
The application must detect and handle timestamp roll over when calculating execution time.The kernelTimestampValidBits must be used to determine the maximum value of the timestamp to detect roll over.
// Note: ZE_STRUCTURE_TYPE_DEVICE_PROPERTIES is deprecated since 1.17 for timer resolution queries. // Use ZE_STRUCTURE_TYPE_DEVICE_PROPERTIES_1_2 to obtain timerResolution in cycles/sec. ze_device_properties_t deviceProperties {}; deviceProperties.stype = ZE_STRUCTURE_TYPE_DEVICE_PROPERTIES_1_2; zeDeviceGetProperties(hDevice, &deviceProperties); // timerResolution is the timer frequency in cycles/sec (Hz) when // stype == ZE_STRUCTURE_TYPE_DEVICE_PROPERTIES_1_2. // Build a mask of kernelTimestampValidBits ones, used to detect counter roll over. // (Avoid ~(-1L << bits): shifting a signed value is undefined behavior, and // long is only 32 bits on some platforms, e.g. Windows.) const uint64_t timestampMaxValue = ( deviceProperties.kernelTimestampValidBits >= 64 ) ? ~(uint64_t)0 : ( (uint64_t)1 << deviceProperties.kernelTimestampValidBits ) - 1; // Create event pool ze_event_pool_desc_t tsEventPoolDesc = { ZE_STRUCTURE_TYPE_EVENT_POOL_DESC, nullptr, ZE_EVENT_POOL_FLAG_KERNEL_TIMESTAMP, // all events in pool are kernel timestamps 1 // count }; ze_event_pool_handle_t hTSEventPool; zeEventPoolCreate(hContext, &tsEventPoolDesc, 0, nullptr, &hTSEventPool); ze_event_desc_t tsEventDesc = { ZE_STRUCTURE_TYPE_EVENT_DESC, nullptr, 0, // index 0, // no additional memory/cache coherency required on signal 0 // no additional memory/cache coherency required on wait }; ze_event_handle_t hTSEvent; zeEventCreate(hTSEventPool, &tsEventDesc, &hTSEvent); // allocate memory for results ze_device_mem_alloc_desc_t tsResultDesc = { ZE_STRUCTURE_TYPE_DEVICE_MEM_ALLOC_DESC, nullptr, 0, // flags 0 // ordinal }; ze_kernel_timestamp_result_t* tsResult = nullptr; zeMemAllocDevice(hContext, &tsResultDesc, sizeof(ze_kernel_timestamp_result_t), sizeof(uint32_t), hDevice, &tsResult); // Append a signal of a timestamp event into the command list after the kernel executes zeCommandListAppendLaunchKernel(hCommandList, hKernel1, &launchArgs, hTSEvent, 0, nullptr); // Append a query of a timestamp event into the command list zeCommandListAppendQueryKernelTimestamps(hCommandList, 1, &hTSEvent, tsResult, nullptr, hEvent, 1, &hTSEvent); // Execute the command list with the signal zeCommandQueueExecuteCommandLists(hCommandQueue, 1, &hCommandList, nullptr); // Wait on event to complete zeEventHostSynchronize(hEvent, 0); // Calculation execution time(s) // First compute the elapsed tick count on each timeline, handling counter roll over. uint64_t globalElapsed = ( tsResult->global.kernelEnd >= tsResult->global.kernelStart ) ? ( tsResult->global.kernelEnd - tsResult->global.kernelStart ) // no wrap : ( timestampMaxValue - tsResult->global.kernelStart ) + tsResult->global.kernelEnd + 1; // counter wrapped uint64_t contextElapsed = ( tsResult->context.kernelEnd >= tsResult->context.kernelStart ) ? ( tsResult->context.kernelEnd - tsResult->context.kernelStart ) // no wrap : ( timestampMaxValue - tsResult->context.kernelStart ) + tsResult->context.kernelEnd + 1; // counter wrapped // timerResolution is in cycles/sec (Hz), so nanoseconds = (tick count) / frequency * NS_IN_SEC. // Multiply by NS_IN_SEC first to preserve precision. const double NS_IN_SEC = 1e9; double globalTimeInNs = (double)globalElapsed * NS_IN_SEC / (double)deviceProperties.timerResolution; double contextTimeInNs = (double)contextElapsed * NS_IN_SEC / (double)deviceProperties.timerResolution; ...
Event synchronization mode#
User can adjust Event synchronization modes by passing ze_event_sync_mode_desc_t struct as pNext during Event creation.
Low power wait#
When ZE_EVENT_SYNC_MODE_FLAG_LOW_POWER_WAIT flag is enabled, driver will optimize Event host synchronization calls like zeEventHostSynchronize to use CPU threads more efficiently. For example, instead of active polling on memory location, it may use OS methods to sleep CPU thread. Changing this mode may impact completion latency.
Interrups#
When ZE_EVENT_SYNC_MODE_FLAG_SIGNAL_INTERRUPT flag is enabled, driver may program additional GPU commands related to signaling Event on the Device. Those commands will generate system interrupt. Interrupt may be used as additional signal to wake up CPU thread that is waiting for Event completion in low power mode. Driver may select which API calls are applicable for generating interrupts.
Additionally, user may provide external interrupt id (ZE_EVENT_SYNC_MODE_FLAG_EXTERNAL_INTERRUPT_WAIT). OS methods will be used for Event host synchronization calls, to optimize waiting for completion. Similar to low power mode. It can be used only with Counter Based Events.
Counter Based Events#
This type of event, referred to as a Counter Based (CB) Event, does not require an event pool, as the related allocations are managed internally by the driver. This reduces the overhead on the host for managing pool allocations. The CB Event can only be signaled on the GPU using an in-order command list.
Every in-order command list has an internal submission counter that is updated with each append call. This counter manages internal in-order dependencies. The next append call waits for that counter implicitly. Note that some operations may be optimized, and the counter value may not directly correspond to the number of append calls.
When a CB Event is passed as a signal event, it points to a specific counter value and memory location. Since the command list manages the counter allocation, this method avoids producing additional GPU memory operations (except timestamps). As a result, users do not need to explicitly control event completion before reusing it.
Key features#
After creation, a CB Event is initially marked as completed. The completion state changes if the event is assigned as a signalEvent to an append call or if external storage is specified during creation.
CB Event can be waited for from any command list type.
zeEventHostReset is not allowed. Can be reused on any in-order command list without explicit reset. A new API call just replaces its previous state (counter/allocation)
zeEventHostSignal is not allowed. Can be signaled only from in-order command list
No need to wait for completion before reusing/destroying
CB Event doesn’t own any memory allocations. Can be reused/destroyed with low cost. Timestamp allocation is also handled internally by the Driver
A CB Event’s device association is not fixed at creation. It re-associates with the signaling device on each signal operation. See Device association.
IPC sharing is one-directional. IPC CB Event opened in different process can be used only for waiting. If original Event state is changed (for example by next append call) and second process needs to see that update, IPC handle must be opened again.
Regular command list (known as recorded or non-immediate) is a special use case for CB Events. Will be described in separate section
When Event is reset (assigned as signal event to new append call), new timestamp data storage is provided implicitly. User can immediately query new data, without handling the completion
Event can be destroyed without waiting for completion, even if profiling is enabled
Regular Event rely on memory state controlled by the user (explicit Reset calls). CB Event represents host programming sequence, without managing the state. For example:
zeEventCounterBasedCreate(context, device, &desc, &event1); // counter not yet assigned zeCommandListAppendLaunchKernel(cmdList1, kernel, &groupCount, &event1, 0, nullptr); // assigned counter=X on memory CL1_alloc zeCommandListAppendLaunchKernel(cmdList2, kernel, &groupCount, nullptr, 1, &event1); // cmdList2 waits for counter=X on memory CL1_alloc // reuse without waiting/reset zeCommandListAppendLaunchKernel(cmdList3, kernel, &groupCount, &event1, 0, nullptr); // Replace state. Assigned counter=Y on memory CL3_alloc // Event1 is implicitly reset to different state. // cmdList2 can be still running on GPU. It waits for counter=X on memory CL1_alloc. // Its also safe to delete Event object. zeEventHostSynchronize(event1, UINT32_MAX); // wait for counter=Y on memory CL3_alloc
Device association#
Unlike Regular Events, a CB Event’s device association is not fixed by the device passed to zeEventCounterBasedCreate. Its association follows the latest signaling point:
After creation, the Event is associated with the device passed to zeEventCounterBasedCreate. This initial association does not restrict on which device the Event may later be signaled.
When the Event is passed as a signal event to an append call, it drops its previous tracking point and re-associates with the device on which that command list was created. The Event may be signaled on any device, regardless of the device used to create it or the device that signaled it previously. No peer-to-peer access between the previous and the new signaling device is required.
Waiting on the Event (for example zeCommandListAppendWaitOnEvents) does not change its association. The waiting device must have peer-to-peer access to the device that last had the Event enqueued for signaling (or, if the Event has not been enqueued for signaling yet, the device it is currently associated with).
zeEventCounterBasedCreate(context, deviceA, &desc, &event); // associated with deviceA zeCommandListAppendSignalEvent(cmdListDeviceB, event); // re-associates with deviceB (no P2P deviceA<->deviceB required) zeCommandListAppendWaitOnEvents(cmdListDeviceC, 1, &event); // deviceC must have P2P access to deviceB
This is also the basis for IPC sharing: an opened IPC CB Event tracks the signaling device and can be waited on from any device that has peer-to-peer access to it.
IPC sharing#
As mentioned previously, signaling CB Event replaces its state. This is why IPC sharing is one-directional. Opened event can be used only for waiting/querying (on host and GPU).
Both Event object (original and shared) are independent. There is no need to wait for completion before reusing. Second process points to the original state until zeEventCounterBasedCloseIpcHandle is called. Original Event state may be changed without waiting for completion. Second process is not affected.
Counter Based Event has dedicated API calls to handle IPC operations:zeEventCounterBasedGetIpcHandle, zeEventCounterBasedOpenIpcHandle, zeEventCounterBasedCloseIpcHandle
Timestamps are not allowed for IPC sharing.
Obtaining counter memory and value#
User may obtain counter memory location and value using zeEventCounterBasedGetDeviceAddress. For example, waiting for completion outside the L0 Driver. If Event state is replaced by new append call or zeCommandQueueExecuteCommandLists that signals such Event, below API must be called again to obtain new data.
Multi directional dependencies on Regular command lists#
Regular command list with overlapping dependencies may be executed multiple times. For example, two command lists are executed in parallel with bi-directional dependencies. Its important to understand counter (Event) state transition, to correctly reflect users intention.
regularCmdList1: (A) -------------> (wait for B) -----> (C)
| ^
| |
V |
regularCmdList2: (wait for A) -------------> (B) -----> (D)
In this example, all Events are synchronized to “ready” state after the first execution. It means that second execution of regularCmdList1 waits again for “ready” {1->2->3} state of regularCmdList2 (first execution) instead of {4->5->6}. This is because regularCmdList2 was not yet executed for the second time. And their counters were not updated.
First execution:
// All Events are in "not ready" state zeCommandQueueExecuteCommandLists(cmdQueue1, 1, ®ularCmdList1, nullptr); // Counter updated to {1->2->3} zeCommandQueueExecuteCommandLists(cmdQueue2, 1, ®ularCmdList2, nullptr); // Counter updated to {1->2->3} // All Events are "ready" now zeCommandQueueSynchronize(cmdQueue1, timeout); // wait for counter=3 zeCommandQueueSynchronize(cmdQueue2, timeout); // wait for counter=3
Second execution:
// regularCmdList1 waits for "ready" {1->2->3} Events from first execution of regularCmdList2
// regularCmdList1 changes Events state to "not ready"
zeCommandQueueExecuteCommandLists(cmdQueue1, 1, ®ularCmdList1, nullptr); // Counter updated to {4->5->6}
// regularCmdList2 waits for "not ready" {4->5->6} Events from second execution of regularCmdList1
zeCommandQueueExecuteCommandLists(cmdQueue2, 1, ®ularCmdList2, nullptr); // Counter updated to {4->5->6}
Different approach:
To avoid above situation, user must remove all bi-directional dependencies. By using single command list (if possible) or split the workload into different command lists with single-directional dependencies.
Using Counter Based Events for such scenarios is not always the most optimal usage mode. It may be better to use Regular Events with explicit Reset calls.
External synchronization allocation#
User may optionally specify externally managed counter allocation and value. This can be done by passing ze_event_counter_based_external_sync_allocation_desc_t as extension of ze_event_counter_based_desc_t
Requirements:
Counter allocation is managed by the user
User must ensure device allocation (deviceAddress) residency (zeContextMakeMemoryResident). It must be GPU accessible USM allocation
Host allocation (hostAddress) must be CPU accessible USM allocation (eg. waiting for completion)
User is responsible for updating both memory locations to >= completionValue to signal Event completion
Using such event for signaling on new API call, replaces the state (as described previously)
Driver defines a maximum value supported for externally managed counter storage. User must query it via zeDeviceGetCounterBasedEventMaxValue prior to event creation.
completionValue provided in ze_event_counter_based_external_sync_allocation_desc_t must not exceed the value returned by zeDeviceGetCounterBasedEventMaxValue. Otherwise zeEventCounterBasedCreate returns ZE_RESULT_ERROR_INVALID_ARGUMENT.
Any value written by the user to deviceAddress or hostAddress (including explicit signaling writes) must also not exceed the value returned by zeDeviceGetCounterBasedEventMaxValue. Exceeding this maximum results in undefined behavior.
External aggregate storage#
Aggregated storage event is a special use case for CB Events. It can be signaled from multiple append calls, but waiting requires only one memory compare operation. It can be created by passing ze_event_counter_based_external_aggregate_storage_desc_t as extension of ze_event_counter_based_desc_t.
Requirements:
This extension cannot be used with “external storage” extension
User must ensure device allocation (deviceAddress) residency. It must be accessible by GPU
Driver will use deviceAddress for host synchronization as USM allocation
If Driver is not able to lock provided device allocation for CPU access, host waits are not possible
Apart from signaling operation, driver will not write anything else to the memory. Initial value is fully under users responsiblility
Signaling such event, will not replace its state (as described previously). It can be passed to multiple append calls and each append will increment the storage by incrementValue (atomically) on GPU
Using aggregated event as dependency, requires only one memory compare operation against final value: completionValue >= *deviceAddress
Device storage is under users control. It must be reset by the user if needed
Profiling is not possible if producers originate on different GPUs (different timestamp domains)
User can programatically obtain increment value that would work even if underlying append API would be distributed to multiple engines via zeDeviceGetAggregatedCopyOffloadIncrementValue query.
completionValue provided in ze_event_counter_based_external_aggregate_storage_desc_t must not exceed the value returned by zeDeviceGetCounterBasedEventMaxValue. Otherwise zeEventCounterBasedCreate returns ZE_RESULT_ERROR_INVALID_ARGUMENT.
User is responsible for ensuring that the value aggregated under deviceAddress (initial value plus any number of incrementValue additions performed by signaling append calls or by the user directly) does not exceed the value returned by zeDeviceGetCounterBasedEventMaxValue at any point in time. Exceeding this maximum results in undefined behavior.
Barriers#
There are two types of barriers:
Execution Barriers - used to communicate execution dependencies between commands within a command list or across command queues, devices and/or Host.
Memory Barriers - used to communicate memory coherency dependencies between commands within a command list or across command queues, devices and/or Host.
The following pseudo-code demonstrates a sequence for submission of a brute-force execution and global memory barrier:
zeCommandListAppendLaunchKernel(hCommandList, hKernel, &launchArgs, nullptr, 0, nullptr); // Append a barrier into a command list to ensure hKernel1 completes before hKernel2 begins zeCommandListAppendBarrier(hCommandList, nullptr, 0, nullptr); zeCommandListAppendLaunchKernel(hCommandList, hKernel, &launchArgs, nullptr, 0, nullptr); ...
Execution Barriers#
Commands executed on a command list are only guaranteed to start in the same order in which they are submitted; i.e. there is no implicit definition of the order of completion.
Fences provide implicit, coarse-grain control to indicate that all previous commands must complete prior to the fence being signaled.
Events provide explicit, fine-grain control over execution dependencies between commands; allowing more opportunities for concurrent execution and higher device utilization.
The following pseudo-code demonstrates a sequence for submission of a fine-grain execution-only dependency using events:
ze_event_desc_t event1Desc = { ZE_STRUCTURE_TYPE_EVENT_DESC, nullptr, 0, // index 0, // no additional memory/cache coherency required on signal 0 // no additional memory/cache coherency required on wait }; ze_event_handle_t hEvent1; zeEventCreate(hEventPool, &event1Desc, &hEvent1); // Ensure hKernel1 completes before signaling hEvent1 zeCommandListAppendLaunchKernel(hCommandList, hKernel1, &launchArgs, hEvent1, 0, nullptr); // Ensure hEvent1 is signaled before starting hKernel2 zeCommandListAppendLaunchKernel(hCommandList, hKernel2, &launchArgs, nullptr, 1, &hEvent1); ...
Memory Barriers#
Commands executed on a command list are not guaranteed to maintain memory coherency with other commands; i.e. there is no implicit memory or cache coherency.
Fences provide implicit, coarse-grain control to indicate that all caches and memory are coherent across the device and Host prior to the fence being signaled.
Events provide explicit, fine-grain control over cache and memory coherency dependencies between commands; allowing more opportunities for concurrent execution and higher device utilization.
The following pseudo-code demonstrates a sequence for submission of a fine-grain memory dependency using events:
ze_event_desc_t event1Desc = { ZE_STRUCTURE_TYPE_EVENT_DESC, nullptr, 0, // index ZE_EVENT_SCOPE_FLAG_DEVICE, // ensure memory coherency across device before event signaled 0 // no additional memory/cache coherency required on wait }; ze_event_handle_t hEvent1; zeEventCreate(hEventPool, &event1Desc, &hEvent1); // Ensure hKernel1 memory writes are fully coherent across the device before signaling hEvent1 zeCommandListAppendLaunchKernel(hCommandList, hKernel1, &launchArgs, hEvent1, 0, nullptr); // Ensure hEvent1 is signaled before starting hKernel2 zeCommandListAppendLaunchKernel(hCommandList, hKernel2, &launchArgs, nullptr, 1, &hEvent1); ...
Range-based Memory Barriers#
Range-based memory barriers provide explicit control of which cachelines require coherency.
The following pseudo-code demonstrates a sequence for submission of a range-based memory barrier:
zeCommandListAppendLaunchKernel(hCommandList, hKernel1, &launchArgs, nullptr, 0, nullptr); // Ensure memory range is fully coherent across the device after hKernel1 and before hKernel2 zeCommandListAppendMemoryRangesBarrier(hCommandList, 1, &size, &ptr, nullptr, 0, nullptr); zeCommandListAppendLaunchKernel(hCommandList, hKernel2, &launchArgs, nullptr, 0, nullptr); ...
Modules and Kernels#
There are multiple levels of constructs needed for executing kernels on the device:
Modules represent a single translation unit that consists of kernels that have been compiled together.
Kernels represent the kernel within the module that will be launched directly from a command list.
The following diagram provides a high-level overview of the major parts of the system.
Modules#
Modules can be created from an IL or directly from native format using zeModuleCreate.
zeModuleCreate takes a format argument that specifies the input format.
zeModuleCreate performs a compilation step when format is IL.
The following pseudo-code demonstrates a sequence for creating a module from an OpenCL kernel:
__kernel void image_scaling( __read_only image2d_t src_img,
__write_only image2d_t dest_img,
uint WIDTH, // resized width
uint HEIGHT ) // resized height
{
int2 coor = (int2)( get_global_id(0), get_global_id(1) );
float2 normCoor = convert_float2(coor) / (float2)( WIDTH, HEIGHT );
float4 color = read_imagef( src_img, SMPL_PREF, normCoor );
write_imagef( dest_img, coor, color );
}
...
// OpenCL C kernel has been compiled to SPIRV IL (pImageScalingIL) ze_module_desc_t moduleDesc = { ZE_STRUCTURE_TYPE_MODULE_DESC, nullptr, ZE_MODULE_FORMAT_IL_SPIRV, ilSize, pImageScalingIL, nullptr, nullptr }; ze_module_handle_t hModule; zeModuleCreate(hContext, hDevice, &moduleDesc, &hModule, nullptr); ...
Module Build Options#
Module build options can be passed with ze_module_desc_t as a string.
Build Option |
Description |
Default |
Device Support |
|---|---|---|---|
-ze-opt-disable |
Disable optimizations. |
Disabled |
All |
-ze-opt-level |
Specifies optimization level for compiler. Levels are implementation specific.
|
2 |
All |
-ze-opt-greater-than-4GB-buffer-required |
Use 64-bit offset calculations for buffers. |
Disabled |
GPU |
-ze-opt-large-register-file |
Increase number of registers available to threads. |
Disabled |
GPU |
-ze-opt-has-buffer-offset-arg |
Extend stateless to stateful optimization to more cases with the use of additional offset (e.g. 64-bit pointer to binding table with 32-bit offset). |
Disabled |
GPU |
-g |
Include debugging information. |
Disabled |
GPU |
Module Specialization Constants#
SPIR-V supports specialization constants that allow certain constants to be updated to new values during runtime execution. Each specialization constant in SPIR-V has an identifier and default value. The zeModuleCreate function allows for an array of constants and their corresponding identifiers to be passed in to override the constants in the SPIR-V module.
// Spec constant overrides for group size. ze_module_constants_t specConstants = { 3, pGroupSizeIds, pGroupSizeValues }; // OpenCL C kernel has been compiled to SPIRV IL (pImageScalingIL) ze_module_desc_t moduleDesc = { ZE_STRUCTURE_TYPE_MODULE_DESC, nullptr, ZE_MODULE_FORMAT_IL_SPIRV, ilSize, pImageScalingIL, nullptr, &specConstants }; ze_module_handle_t hModule; zeModuleCreate(hContext, hDevice, &moduleDesc, &hModule, nullptr); ...
Note: Specialization constants are only handled at module create time and therefore if you need to change them then you’ll need to compile a new module.
Module Build Log#
The zeModuleCreate function can optionally generate a build log object ze_module_build_log_handle_t.
... ze_module_build_log_handle_t buildlog; ze_result_t result = zeModuleCreate(hContext, hDevice, &desc, &module, &buildlog); // Only save build logs for module creation errors. if (result != ZE_RESULT_SUCCESS) { size_t szLog = 0; zeModuleBuildLogGetString(buildlog, &szLog, nullptr); char_t* strLog = allocate(szLog); zeModuleBuildLogGetString(buildlog, &szLog, strLog); // Save log to disk. ... free(strLog); } zeModuleBuildLogDestroy(buildlog);
Dynamically Linked Modules#
Modules may be interdependent, i.e., a module may contain functions and global variables that are used and defined by different modules. Such a module is said to have both import as well as export linkage requirements. Private variables are not transferrable between linked modules, i.e., their visibility is limited to the module in which they are defined. Only global variables or static values passed to linked functions are visible between linked modules. All the import linkage requirements of a module must be satisfied before a kernel can be created from that module. Modules that have no imports do not need to be linked. Dynamically linking modules together is performed using zeModuleDynamicLink. Modules cannot have ambiguous import dependencies, i.e., imported functions and global variables must only be defined once in any given set of modules passed to zeModuleDynamicLink. Imports are linked only once. Once all the import dependencies of a module have been linked, the use of that fully import-linked module in subsequent calls to zeModuleDynamicLink will not cause the imports of the module to be re-linked.
The zeModuleDynamicLink function can optionally generate a link log object ze_module_build_log_handle_t.
... ze_module_build_log_handle_t linklog; ze_result_t result = zeModuleDynamicLink(numModules, &hModules, &hLinklog); // Check if there are linking errors if (result == ZE_RESULT_ERROR_MODULE_LINK_FAILURE) { size_t szLog = 0; zeModuleBuildLogGetString(linklog, &szLog, nullptr); char_t* strLog = allocate(szLog); zeModuleBuildLogGetString(linklog, &szLog, strLog); // Save log to disk. ... free(strLog); } zeModuleBuildLogDestroy(linklog);
Module Caching with Native Binaries#
Disk caching of modules is not supported by the driver. If a disk cache for modules is desired, then it is the responsibility of the application to implement this using zeModuleGetNativeBinary.
...
// compute hash for pIL and check cache.
...
if (cacheUpdateNeeded)
{
size_t szBinary = 0;
zeModuleGetNativeBinary(hModule, &szBinary, nullptr);
uint8_t* pBinary = allocate(szBinary);
zeModuleGetNativeBinary(hModule, &szBinary, pBinary);
// cache pBinary for corresponding IL
...
free(pBinary);
}
Also, note that the native binary will retain all debug information that is associated with the module. This allows debug capabilities for modules that are created from native binaries.
Built-in Kernels#
Built-in kernels are not supported but can be implemented by an upper level runtime or library using the native binary interface.
Kernels#
A Kernel is a reference to a kernel within a module and it supports both explicit and implicit kernel arguments along with data needed for launch.
The following pseudo-code demonstrates a sequence for creating a kernel from a module:
ze_kernel_desc_t kernelDesc = { ZE_STRUCTURE_TYPE_KERNEL_DESC, nullptr, 0, // flags "image_scaling" }; ze_kernel_handle_t hKernel; ze_result_t result = zeKernelCreate(hModule, &kernelDesc, &hKernel); // Check if there are unresolved imports if (result == ZE_RESULT_ERROR_INVALID_MODULE_UNLINKED) { // Un-resolvable import dependencies found in module! ... } // Check to see if the kernel "image_scaling" was found in the supplied module if (result == ZE_RESULT_ERROR_INVALID_KERNEL_NAME) { // Kernel "image_scaling" not found in module! ... } ...
Kernel Properties#
Use zeKernelGetProperties to query invariant properties from a Kernel object.
... ze_kernel_properties_t kernelProperties; zeKernelGetProperties(hKernel, &kernelProperties); ...
See ze_kernel_properties_t for more information for kernel properties.
Execution#
Kernel Group Size#
The group size for a kernel can be set using zeKernelSetGroupSize. If a group size is not set prior to appending a kernel into a command list then a default will be chosen. The group size can be updated over a series of append operations. The driver will copy the group size information when appending the kernel into the command list.
zeKernelSetGroupSize(hKernel, groupSizeX, groupSizeY, 1); ...
The API supports a query for suggested group size when providing the global size. This function ignores the group size that was set on the kernel using zeKernelSetGroupSize.
// Find suggested group size for processing image. uint32_t groupSizeX; uint32_t groupSizeY; zeKernelSuggestGroupSize(hKernel, imageWidth, imageHeight, 1, &groupSizeX, &groupSizeY, nullptr); zeKernelSetGroupSize(hKernel, groupSizeX, groupSizeY, 1); ...
Kernel Arguments#
Kernel arguments represent only the explicit kernel arguments that are within brackets e.g. func(arg1, arg2, …).
Use zeKernelSetArgumentValue to setup arguments for a kernel launch.
The zeCommandListAppendLaunchKernel et al. functions will make a copy of the kernel arguments to send to the device.
Kernel arguments can be updated at any time and used across multiple append calls.
Note that when using images as arguments, implementation can check whether the image format is valid as an argument to a SPIRv module. If the image format is invalid, implementation may return ZE_RESULT_ERROR_UNSUPPORTED_IMAGE_FORMAT.
If the image type allocated is valid, implementation cannot return unsupported during image creation. The images may be used in kernels that are not limited to the SPIRv image types, for example VC Runtime built Native binaries that support more image types than SPIRv and do not use the channel data type argument.
Since SPIRv channel type and OpenCL images share the same channel data type restrictions, implementation can reuse the OpenCL type check to verify if the image can be set as argument for a kernel in SPIRv Module.
The following pseudo-code demonstrates a sequence for setting kernel arguments and launching the kernel:
// Bind arguments zeKernelSetArgumentValue(hKernel, 0, sizeof(ze_image_handle_t), &src_image); zeKernelSetArgumentValue(hKernel, 1, sizeof(ze_image_handle_t), &dest_image); zeKernelSetArgumentValue(hKernel, 2, sizeof(uint32_t), &width); zeKernelSetArgumentValue(hKernel, 3, sizeof(uint32_t), &height); ze_group_count_t launchArgs = { numGroupsX, numGroupsY, 1 }; // Append launch kernel zeCommandListAppendLaunchKernel(hCommandList, hKernel, &launchArgs, nullptr, 0, nullptr); // Update image pointers to copy and scale next image. zeKernelSetArgumentValue(hKernel, 0, sizeof(ze_image_handle_t), &src2_image); zeKernelSetArgumentValue(hKernel, 1, sizeof(ze_image_handle_t), &dest2_image); // Append launch kernel zeCommandListAppendLaunchKernel(hCommandList, hKernel, &launchArgs, nullptr, 0, nullptr); ...
Kernel Launch#
In order to launch a kernel on the device an application must call one of the AppendLaunchKernel-style functions for a command list. The most basic version of these is zeCommandListAppendLaunchKernel which takes a command list, kernel handle, launch arguments, and an optional synchronization event used to signal completion. The launch arguments contain thread group dimensions.
// compute number of groups to launch based on image size and group size. uint32_t numGroupsX = imageWidth / groupSizeX; uint32_t numGroupsY = imageHeight / groupSizeY; ze_group_count_t launchArgs = { numGroupsX, numGroupsY, 1 }; // Append launch kernel zeCommandListAppendLaunchKernel(hCommandList, hKernel, &launchArgs, nullptr, 0, nullptr);
The function zeCommandListAppendLaunchKernelIndirect allows the launch parameters to be supplied indirectly in a buffer that the device reads instead of the command itself. This allows for the previous operations on the device to generate the parameters.
ze_group_count_t* pIndirectArgs; ... zeMemAllocDevice(hContext, &desc, sizeof(ze_group_count_t), sizeof(uint32_t), hDevice, &pIndirectArgs); // Append launch kernel - indirect zeCommandListAppendLaunchKernelIndirect(hCommandList, hKernel, &pIndirectArgs, nullptr, 0, nullptr);
Cooperative Kernels#
Cooperative kernels allow sharing of data and synchronization across all launched groups in a safe manner. To support this there is a zeCommandListAppendLaunchCooperativeKernel that allows launching groups that can cooperate with each other. The command list must be submitted to a command queue that was created with an ordinal of a command queue group that has the ZE_COMMAND_QUEUE_GROUP_PROPERTY_FLAG_COOPERATIVE_KERNELS flags set. The maximum number of groups for a cooperative kernel launch may be determined by calling zeKernelSuggestMaxCooperativeGroupCount.
// query and set kernel work-group size uint32_t groupSizeX; uint32_t groupSizeY; zeKernelSuggestGroupSize(hKernel, imageWidth, imageHeight, 1, &groupSizeX, &groupSizeY, nullptr); zeKernelSetGroupSize(hKernel, groupSizeX, groupSizeY, 1); // query the maximum cooperative kernel launch for the kernel uint32_t maxGroupCount; zeKernelSuggestMaxCooperativeGroupCount(hKernel, &maxGroupCount); // the total group count must be smaller than the queried maximum assert(numGroupsX * numGroupsY * numGroupsZ < maxGroupCount); ze_group_count_t launchArgs = { numGroupsX, numGroupsY, numGroupsZ }; // Append launch cooperative kernel zeCommandListAppendLaunchCooperativeKernel(hCommandList, hKernel, &launchArgs, nullptr, 0, nullptr);
Sampler#
The API supports Sampler objects that represent state needed for sampling images from within kernels. The zeSamplerCreate function takes a sampler descriptor (ze_sampler_desc_t):
Sampler Field |
Description |
|---|---|
Address Mode |
Determines how out-of-bounds accesses are handled. See ze_sampler_address_mode_t. |
Filter Mode |
Specifies which filtering mode to use. See ze_sampler_filter_mode_t. |
Normalized |
Specifies whether coordinates for addressing image are normalized [0,1] or not. |
The following pseudo-code demonstrates the creation of a sampler object and passing it as a kernel argument:
// Setup sampler for linear filtering and clamp out of bounds accesses to edge. ze_sampler_desc_t desc = { ZE_STRUCTURE_TYPE_SAMPLER_DESC, nullptr, ZE_SAMPLER_ADDRESS_MODE_CLAMP, ZE_SAMPLER_FILTER_MODE_LINEAR, false }; ze_sampler_handle_t sampler; zeSamplerCreate(hContext, hDevice, &desc, &sampler); ... // The sampler can be passed as a kernel argument. zeKernelSetArgumentValue(hKernel, 0, sizeof(ze_sampler_handle_t), &sampler); // Append launch kernel zeCommandListAppendLaunchKernel(hCommandList, hKernel, &launchArgs, nullptr, 0, nullptr);
Formatted Output#
The API supports the ability to print formatted output from a kernel using functions such as printf.
Calls to print formatted output will cause data to be written to an internal buffer, where the size of the internal buffer is given by ze_device_module_properties_t.printfBufferSize.
When the internal buffer becomes full, additional calls to print formatted output will return an error code.
There is no ordering guarantee for the formatted output.
If multiple work-items make multiple calls to printf, the output from one work-item may appear intermixed with output from other work-items.
On some devices, the internal buffer may not contain the formatted output itself, and instead the formatting may occur on the host. Additionally, the final formatting may not occur and the output may not be flushed to the output stream until the event associated with the kernel launch is complete. To ensure all output has been flushed to the output stream, wait on the event associated with the kernel launch, or wait for the kernel launch to complete using a coarser-grained synchronization method such as zeFenceHostSynchronize or zeCommandQueueSynchronize.
Advanced#
Environment Variables#
The following table documents the supported knobs for overriding default functional behavior.
Category |
Name |
Values |
Description |
|---|---|---|---|
Device |
ZE_FLAT_DEVICE_HIERARCHY |
{COMPOSITE, FLAT, COMBINED} |
Defines device hierarchy model exposed by Level Zero driver implementation |
ZE_AFFINITY_MASK |
list |
Forces driver to only report devices (and sub-devices) as specified by values |
|
ZE_ENABLE_PCI_ID_DEVICE_ORDER |
{0, 1} |
Forces driver to report devices from lowest to highest PCI bus ID |
|
Memory |
ZE_SHARED_FORCE_DEVICE_ALLOC |
{0, 1} |
Forces all shared allocations into device memory |
Drivers |
ZEL_DRIVERS_ORDER |
string |
Defines ordering of drivers reported to user. See Driver Ordering section for syntax details. |
Driver Ordering#
The Level Zero Runtime provides the ability to change the default driver used in “zer” Level Zero Runtime APIs through an environment variable to enable flexible driver selection and ordering.
This environment variable is read by the Level Zero Loader to determine the order in which drivers are initialized and used.
A robust driver selector is created considering multiple drivers of different types with the following supported syntax:
Specify specific type and index within that type:
ZEL_DRIVERS_ORDER=<driver_type>:<driver_index>[,<driver_type>:<driver_index>]Specify specific type:
ZEL_DRIVERS_ORDER=<driver_type>[,<driver_type>]Specify only the driver index (Refers to the original global driver index):
ZEL_DRIVERS_ORDER=<driver_index>[,<driver_index>]
Supported Driver Types:
DISCRETE_GPU_ONLYGPUINTEGRATED_GPU_ONLYNPU
This allows ordering all the drivers or reordering the drivers with those specified at the front. Due to reliance of other libraries that drivers are not “masked”, one cannot mask drivers and devices through an environment variable read at the loader level.
Devices or driver types not explicitly specified in the ZEL_DRIVERS_ORDER environment variable will still be exposed by the Level Zero Loader, but will appear at the end of the driver list in their default order.
Example Usage
ZEL_DRIVERS_ORDER = DISCRETE_GPU_ONLY:1, NPUOn a system with 2 GPU Drivers (discrete:0, discrete:1) and 1 NPU Driver, where the default order is : Discrete:0, Discrete:1, NPU, this setting will change the order to:
Discrete:1, NPU:0, Discrete:0
Index 0 used in zer == Discrete:1
ZEL_DRIVERS_ORDER = 2,0On a system with 2 GPU Drivers (discrete, integrated) and 1 NPU Driver, where the default order is : Discrete, integrated, NPU, this setting will change the order to:
NPU, Discrete, Integrated
Index 0 used in zer == NPU
ZEL_DRIVERS_ORDER = GPU:1, NPU:0On a system with 2 GPU Drivers (discrete, integrated) and 1 NPU Driver, where the default order is : Discrete, Integrated, NPU, and the indexes per type are:
GPU: Discrete, Integrated
NPU: NPU
Resulting order:
Integrated, NPU, Discrete
Index 0 used in zer == Integrated
ZEL_DRIVERS_ORDER = NPUOn a system with 2 GPU Drivers (discrete, integrated) and 1 NPU Driver, where the default order is : Discrete, integrated, NPU, this setting will change the order to:
NPU, Discrete, Integrated
Index 0 used in zer == NPU
Device Discovery Tool
For debugging and system inspection purposes, you can use the show_devices_l0 tool from the Intel compute-benchmarks repository to easily view driver information and device properties on your system:
# Clone and build the compute-benchmarks repository git clone intel/compute-benchmarks.git cd compute-benchmarks mkdir build && cd build cmake .. make show_devices_l0 # Run the tool to display driver index, driver type, and device information ./source/tools/show_devices_l0
This tool will display:
Driver index and driver type for each Level-Zero driver
Device properties including device type, name, and capabilities
Sub-device information if available
Memory properties and other device-specific details
The show_devices_l0 tool provides a convenient way to inspect the Level-Zero driver and device hierarchy, which is particularly useful when configuring driver ordering with the ZEL_DRIVERS_ORDER environment variable.
Device Hierarchy#
ZE_FLAT_DEVICE_HIERARCHY allows users to select the device hierarchy model with which the underlying hardware is exposed and the types of devices returned with zeDeviceGet.
When setting to COMPOSITE, zeDeviceGet returns all the devices that do not have a root-device. Traversing the device hierarchy is possible by querying sub-devices with zeDeviceGetSubDevices and root-devices with zeDeviceGetRootDevice. Driver implementation may perform implicit optimizations to submissions and allocations done in the root-devices.
When setting to FLAT, zeDeviceGet returns all the devices that do not have sub-devices. Traversing the device hierarchy is not possible, with zeDeviceGetSubDevices returning always a count of 0 device handles and zeDeviceGetRootDevice returning nullptr. This mode allows Level Zero driver implementations to optimize execution and memory allocations by removing any overhead required to account for simultaneous use of root-devices and sub-devices in the same application.
When setting to COMBINED, zeDeviceGet returns all the devices that do not have sub-devices. Traversing the device hierarchy is possible by querying sub-devices with zeDeviceGetSubDevices and root-devices with zeDeviceGetRootDevice. Driver implementation may perform implicit optimizations to submissions and allocations done in the root-devices.
Devices returned by SYSMAN APIs are not affected by ZE_FLAT_DEVICE_HIERARCHY and always return the top-level device handles corresponding to the physical devices.
Affinity Mask#
The affinity mask allows an application or tool to restrict which devices, and sub-devices, are visible to 3rd-party libraries or applications in another process, respectively. The affinity mask affects the number of handles returned from zeDeviceGet and zeDeviceGetSubDevices. The affinity mask is specified via an environment variable as a comma-seperated list of device and/or subdevice ordinals. The values are specific to system configuration; e.g., the number of devices and the number of sub-devices for each device. The values are specific to the order in which devices are reported by the driver; i.e., the first device maps to ordinal 0, the second device to ordinal 1, and so forth. If the affinity mask is not set, then all devices and sub-devices are reported; as is the default behavior.
The affinity mask masks the devices as defined by value set in the ZE_FLAT_DEVICE_HIERARCHY environment variable, i.e., a Level Zero driver shall read first ZE_FLAT_DEVICE_HIERARCHY to determine the device handles to be used by the application and then interpret the values passed in ZE_AFFINITY_MASK based on the device model selected.
The order of the devices reported by the zeDeviceGet is implementation-specific and not affected by the order of devices in the affinity mask.
The order of the devices reported by the zeDeviceGet can be forced to be consistent by setting the ZE_ENABLE_PCI_ID_DEVICE_ORDER environment variable.
The following examples demonstrate proper usage for a system configuration composed of two physical devices, each of which can be further sub-divided into four smaller devices. For the purpose of these examples, we will refer to the two physical devices as parent devices and to the smaller sub-devices as tiles.
When setting the ZE_AFFINITY_MASK with different values, and ZE_FLAT_DEVICE_HIERARCHY to COMPOSITE, the following scenarios may occur:
ZE_AFFINITY_MASK = 0, 1: all parent devices and tiles are reported (same as default):
Parent Device |
Tile |
Exposed |
Device Handle Used |
|---|---|---|---|
0 |
0 |
Yes |
Device handle 0, sub-device handle 0 |
0 |
1 |
Yes |
Device handle 0, sub-device handle 1 |
0 |
2 |
Yes |
Device handle 0, sub-device handle 2 |
0 |
3 |
Yes |
Device handle 0, sub-device handle 3 |
1 |
0 |
Yes |
Device handle 1, sub-device handle 0 |
1 |
1 |
Yes |
Device handle 1, sub-device handle 1 |
1 |
2 |
Yes |
Device handle 1, sub-device handle 2 |
1 |
3 |
Yes |
Device handle 1, sub-device handle 3 |
ZE_AFFINITY_MASK = 0: only parent device 0 is reported as device handle 0, with all its tiles reported as sub-device handles:
Parent Device |
Tile |
Exposed |
Device Handle Used |
|---|---|---|---|
0 |
0 |
Yes |
Device handle 0, sub-device handle 0 |
0 |
1 |
Yes |
Device handle 0, sub-device handle 1 |
0 |
2 |
Yes |
Device handle 0, sub-device handle 2 |
0 |
3 |
Yes |
Device handle 0, sub-device handle 3 |
1 |
0 |
No |
|
1 |
1 |
No |
|
1 |
2 |
No |
|
1 |
3 |
No |
ZE_AFFINITY_MASK = 1: only parent device 1 is reported as device handle 0, with all its tiles reported as sub-device handles:
Parent Device |
Tile |
Exposed |
Device Handle Used |
|---|---|---|---|
0 |
0 |
No |
|
0 |
1 |
No |
|
0 |
2 |
No |
|
0 |
3 |
No |
|
1 |
0 |
Yes |
Device handle 0, sub-device handle 0 |
1 |
1 |
Yes |
Device handle 0, sub-device handle 1 |
1 |
2 |
Yes |
Device handle 0, sub-device handle 2 |
1 |
3 |
Yes |
Device handle 0, sub-device handle 3 |
ZE_AFFINITY_MASK = 0.0: only tile 0 in parent device 0 is reported as device handle 0:
Parent Device |
Tile |
Exposed |
Device Handle Used |
|---|---|---|---|
0 |
0 |
Yes |
Device handle 0 |
0 |
1 |
No |
|
0 |
2 |
No |
|
0 |
3 |
No |
|
1 |
0 |
No |
|
1 |
1 |
No |
|
1 |
2 |
No |
|
1 |
3 |
No |
ZE_AFFINITY_MASK = 1.1, 1.2: only parent device 1 is reported as device handle 0; with its tiles 1 and 2 reported as its sub-devices 0 and 1, respectively:
Parent Device |
Tile |
Exposed |
Device Handle Used |
|---|---|---|---|
0 |
0 |
No |
|
0 |
1 |
No |
|
0 |
2 |
No |
|
0 |
3 |
No |
|
1 |
0 |
No |
|
1 |
1 |
Yes |
Device handle 0, sub-device handle 0 |
1 |
2 |
Yes |
Device handle 0, sub-device handle 1 |
1 |
3 |
No |
ZE_AFFINITY_MASK = 0.2, 1.3, 1.0, 0.3: both parent devices 0 and 1 are reported as device handles 0 and 1, respectively; parent device 0 reports its tiles 2 and 3 as sub-devices 0 and 1, respectively; parent device 1 reports tiles 0 and 3 as sub-devices 0 and 1, respectively; the order is unchanged:
Parent Device |
Tile |
Exposed |
Device Handle Used |
|---|---|---|---|
0 |
0 |
No |
|
0 |
1 |
No |
|
0 |
2 |
Yes |
Device handle 0, sub-device handle 0 |
0 |
3 |
Yes |
Device handle 0, sub-device handle 1 |
1 |
0 |
Yes |
Device handle 1, sub-device handle 0 |
1 |
1 |
No |
|
1 |
2 |
No |
|
1 |
3 |
Yes |
Device handle 1, sub-device handle 1 |
The following examples show the use of different values in the ZE_AFFINITY_MASK when setting ZE_FLAT_DEVICE_HIERARCHY to FLAT, in the same system with two parent devices and four tiles each. When setting ZE_FLAT_DEVICE_HIERARCHY to FLAT, only the tiles are reported by zeDeviceGet, which means that in this system zeDeviceGet would report up to 8 device handles, with device handles 0 to 3 corresponding to the four tiles in parent device 0, and device handles 4 to 7 corresponding to the four tiles in parent device 1:
ZE_AFFINITY_MASK = 0, 1, 2, 3, 4, 5, 6, 7: all tiles are reported as device handles by zeDeviceGet (same as default):
Parent Device |
Tile |
Exposed |
Device Handle Used |
|---|---|---|---|
0 |
0 |
Yes |
Device handle 0 |
0 |
1 |
Yes |
Device handle 1 |
0 |
2 |
Yes |
Device handle 2 |
0 |
3 |
Yes |
Device handle 3 |
1 |
0 |
Yes |
Device handle 4 |
1 |
1 |
Yes |
Device handle 5 |
1 |
2 |
Yes |
Device handle 6 |
1 |
3 |
Yes |
Device handle 7 |
ZE_AFFINITY_MASK = 0: only tile 0 in parent device 0 is reported as device handle 0:
Parent Device |
Tile |
Exposed |
Device Handle Used |
|---|---|---|---|
0 |
0 |
Yes |
Device handle 0 |
0 |
1 |
No |
|
0 |
2 |
No |
|
0 |
3 |
No |
|
1 |
0 |
No |
|
1 |
1 |
No |
|
1 |
2 |
No |
|
1 |
3 |
No |
ZE_AFFINITY_MASK = 1: only tile 1 in parent device 0 is reported as device handle 0.
Parent Device |
Tile |
Exposed |
Device Handle Used |
|---|---|---|---|
0 |
0 |
No |
|
0 |
1 |
Yes |
Device handle 0 |
0 |
2 |
No |
|
0 |
3 |
No |
|
1 |
0 |
No |
|
1 |
1 |
No |
|
1 |
2 |
No |
|
1 |
3 |
No |
ZE_AFFINITY_MASK = 0, 4: tile 0 from parent device 0 is reported as device handle 0 and tile 0 in parent device 1 is reported as device handle 1:
Parent Device |
Tile |
Exposed |
Device Handle Used |
|---|---|---|---|
0 |
0 |
Yes |
Device handle 0 |
0 |
1 |
No |
|
0 |
2 |
No |
|
0 |
3 |
No |
|
1 |
0 |
Yes |
Device handle 1 |
1 |
1 |
No |
|
1 |
2 |
No |
|
1 |
3 |
No |
ZE_AFFINITY_MASK = 1, 2, 7: tile 1 from parent device 0 is reported as device handle 0, tile 2 in parent device 0 is reported as device handle 1, and tile 3 in parent device 1 is reported as device handle 2:
Parent Device |
Tile |
Exposed |
Device Handle Used |
|---|---|---|---|
0 |
0 |
No |
|
0 |
1 |
Yes |
Device handle 0 |
0 |
2 |
Yes |
Device handle 1 |
0 |
3 |
No |
|
1 |
0 |
No |
|
1 |
1 |
No |
|
1 |
2 |
No |
|
1 |
3 |
Yes |
Device handle 2 |
ZE_AFFINITY_MASK = 0.0: is not valid, as with ZE_FLAT_DEVICE_HIERARCHY set to FLAT, the device handles reported by zeDeviceGet are those which do not contain further sub-devices.
Sub-Device Support#
The API allows support for sub-devices which can enable finer-grained control of scheduling and memory allocation to a sub-partition of the device. There are functions to query and obtain sub-devices, but outside of these functions there are no distinctions between sub-devices and devices. Sub-devices are not required to represent unique partitions of a device; i.e. multiple sub-devices may share the same physical hardware. Furthermore, a sub-device can be partitioned into more sub-devices; e.g. down to a single slice.
Use zeDeviceGetSubDevices to confirm sub-devices are supported and to obtain a sub-device handle. There are additional device properties in ze_device_properties_t for sub-devices. These can be used to confirm a device is a sub-device and to query the sub-device id. This may be used by libraries to determine if an input device handle represents a device or sub-device.
A driver is required to make device memory allocations on the parent device visible to its sub-devices. However, when using a sub-device handle, the driver will attempt to place any device memory allocations in the local memory that is attached to the sub-device. These allocations are only visible to the sub-device, its sub-devices, and so forth. If the API call returns ZE_RESULT_ERROR_OUT_OF_DEVICE_MEMORY, then the application may attempt to retry using the parent device.
When creating command queues for a sub-device, the application must determine the ordinal from calling zeDeviceGetCommandQueueGroupProperties using the sub-device handle. See ze_command_queue_desc_t for more details.
A 16-byte unique device identifier (uuid) can be obtained for a device or sub-device using zeDeviceGetProperties.
// Query for all sub-devices of the device uint32_t subdeviceCount = 0; zeDeviceGetSubDevices(hDevice, &subdeviceCount, nullptr); ze_device_handle_t* allSubDevices = allocate(subdeviceCount * sizeof(ze_device_handle_t)); zeDeviceGetSubDevices(hDevice, &subdeviceCount, &allSubDevices); // Desire is to allocate and dispatch work to sub-device 2. assert(subdeviceCount >= 3); ze_device_handle_t hSubdevice = allSubDevices[2]; // Query sub-device properties. ze_device_properties_t subdeviceProps {}; subDeviceProps.stype = ZE_STRUCTURE_TYPE_DEVICE_PROPERTIES_1_2; // ZE_STRUCTURE_TYPE_DEVICE_PROPERTIES deprecated since 1.17 zeDeviceGetProperties(hSubdevice, &subdeviceProps); assert(subdeviceProps.flags & ZE_DEVICE_PROPERTY_FLAG_SUBDEVICE); // Ensure that we have a handle to a sub-device. assert(subdeviceProps.subdeviceId == 2); // Ensure that we have a handle to the sub-device we asked for. void* pMemForSubDevice2; zeMemAllocDevice(hContext, &desc, memSize, sizeof(uint32_t), hSubdevice, &pMemForSubDevice2); ...
Device Residency#
For devices that do not support page-faults, the driver must ensure that all pages that will be accessed by the kernel are resident before program execution. This can be determined by checking ze_device_properties_t.flags for ZE_DEVICE_PROPERTY_FLAG_ONDEMANDPAGING.
In most cases, the driver implicitly handles residency of allocations for device access. This can be done by inspecting API parameters, including kernel arguments. However, in cases where the devices does not support page-faulting and the driver is incapable of determining whether an allocation will be accessed by the device, such as multiple levels of indirection, there are two methods available:
The application may set the ZE_KERNEL_FLAG_FORCE_RESIDENCY flag during program creation to force all device allocations to be resident during execution.
The application should specify which allocation types will be indirectly accessed, using zeKernelSetIndirectAccess and the following flags, to optimize which allocations are made resident.
If the driver is unable to make all allocations resident, then the call to zeCommandQueueExecuteCommandLists will return ZE_RESULT_ERROR_OUT_OF_DEVICE_MEMORY
Explicit zeContextMakeMemoryResident APIs are included for the application to dynamically change residency as needed.
If the application over-commits device memory, then a call to zeContextMakeMemoryResident will return ZE_RESULT_ERROR_OUT_OF_DEVICE_MEMORY
If the application does not properly manage residency for these cases then the device may experience unrecoverable page-faults.
The following pseudo-code demonstrates a sequence for using coarse-grain residency control for indirect arguments:
struct node {
node* next;
};
node* begin = nullptr;
zeMemAllocHost(hContext, &desc, sizeof(node), 1, &begin);
zeMemAllocHost(hContext, &desc, sizeof(node), 1, &begin->next);
zeMemAllocHost(hContext, &desc, sizeof(node), 1, &begin->next->next);
// 'begin' is passed as kernel argument and appended into command list
zeKernelSetIndirectAccess(hKernel, ZE_KERNEL_INDIRECT_ACCESS_FLAG_HOST);
zeKernelSetArgumentValue(hKernel, 0, sizeof(node*), &begin);
zeCommandListAppendLaunchKernel(hCommandList, hKernel, &launchArgs, nullptr, 0, nullptr);
...
zeCommandQueueExecuteCommandLists(hCommandQueue, 1, &hCommandList, nullptr);
...
The following pseudo-code demonstrates a sequence for using fine-grain residency control for indirect arguments:
struct node {
node* next;
};
node* begin = nullptr;
zeMemAllocHost(hContext, &desc, sizeof(node), 1, &begin);
zeMemAllocHost(hContext, &desc, sizeof(node), 1, &begin->next);
zeMemAllocHost(hContext, &desc, sizeof(node), 1, &begin->next->next);
// 'begin' is passed as kernel argument and appended into command list
zeKernelSetArgumentValue(hKernel, 0, sizeof(node*), &begin);
zeCommandListAppendLaunchKernel(hCommandList, hKernel, &launchArgs, nullptr, 0, nullptr);
...
// Make indirect allocations resident before enqueuing
zeContextMakeMemoryResident(hContext, hDevice, begin->next, sizeof(node));
zeContextMakeMemoryResident(hContext, hDevice, begin->next->next, sizeof(node));
zeCommandQueueExecuteCommandLists(hCommandQueue, 1, &hCommandList, hFence);
// wait until complete
zeFenceHostSynchronize(hFence, UINT32_MAX);
// Finally, evict to free device resources
zeContextEvictMemory(hContext, hDevice, begin->next, sizeof(node));
zeContextEvictMemory(hContext, hDevice, begin->next->next, sizeof(node));
...
Interoperability with Other APIs#
Level-Zero includes general-purpose interoperability mechanisms for memory allocations (both images and device memory) and modules.
Memory allocations may be shared between Level-Zero and other APIs via External Memory Import and Export. Level-Zero supports exporting memory allocations for use in other APIs and importing memory allocations from other APIs.
Modules may be shared between Level-Zero and other APIs via native format binaries, see zeModuleGetNativeBinary and ZE_MODULE_FORMAT_NATIVE.
The following pseudo-code demonstrates interoperability with OpenCL from a OpenCL cl_program to a Level-Zero Kernel:
void* clDeviceBinary; size_t clDeviceBinarySize; clGetProgramInfo(cl_program, CL_PROGRAM_BINARIES, clDeviceBinary, &clDeviceBinarySize); ze_module_desc_t desc = { ZE_STRUCTURE_TYPE_MODULE_DESC, nullptr, ZE_MODULE_FORMAT_NATIVE, clDeviceBinarySize, clDeviceBinary }; zeModuleCreate(hContext, hDevice, &desc, &hModule, nullptr); zeKernelCreate(hModule, nullptr, hKernel); // same Kernel as OpenCL in Level-Zero
Inter-Process Communication#
The API allows sharing of memory objects across different device processes. Since each process has its own virtual address space, there is no guarantee that the same virtual address will be available when the memory object is shared in new process. There are a set of APIs that makes it easier to share the memory objects with ease.
There are two types of Inter-Process Communication (IPC) APIs for using Level-Zero allocations across processes:
Memory#
Physical memory handles (ze_physical_mem_handle_t) may be used as the source for IPC handles
in both zeMemGetIpcHandle and zeMemGetIpcHandleWithProperties. There are two ways to obtain an
IPC handle backed by physical memory:
Direct from a mapped virtual address: After mapping a physical memory object to a virtual address using zeVirtualMemMap, the mapped virtual address pointer can be passed directly to zeMemGetIpcHandle or zeMemGetIpcHandleWithProperties. Only one physical memory object may be associated with a single IPC handle at a time.
From a physical memory handle allocated via
:ref:`zePhysicalMemCreate`\: The handle returned from zePhysicalMemCreate can be used to obtain an IPC handle via zeMemGetIpcHandleWithProperties.
When an IPC handle backed by physical memory is opened in the receiving process via zeMemOpenIpcHandle, the driver assigns a new virtual address in the importing process that maps to the underlying physical memory. No prior zeVirtualMemReserve or zeVirtualMemMap call is required in the importing process.
Note
The driver must not release the underlying physical memory until all IPC handles referencing it have been closed via zeMemCloseIpcHandle or returned via zeMemPutIpcHandle. Applications should ensure that all receiving processes close their IPC handles before the originating process frees the allocation.
The following code examples demonstrate how to use the memory IPC APIs:
First, the allocation is made, packaged, and sent on the sending process:
void* dptr = nullptr; zeMemAllocDevice(hContext, &desc, size, alignment, hDevice, &dptr); ze_ipc_mem_handle_t hIPC; zeMemGetIpcHandle(hContext, dptr, &hIPC); // NOTE: Transferring IPC handles is not a Level Zero API. The application is responsible // for sending the handle to the receiving process using its preferred out of band method // (e.g., Shared memory, TCP/IP, fabric, etc.)
Next, the allocation is received and un-packaged on the receiving process:
// NOTE: Receiving IPC handles is not a Level Zero API. The application is responsible // for receiving the handle from the sending process using its preferred out of band method // (e.g., Shared memory, TCP/IP, fabric, etc.) ze_ipc_mem_handle_t hIPC; void* dptr = nullptr; zeMemOpenIpcHandle(hContext, hDevice, hIPC, 0, &dptr);
Each process may now refer to the same device memory allocation via its
dptr. Note, there is no guaranteed address equivalence for the values ofdptrin each process.To cleanup, first close the handle in the receiving process:
zeMemCloseIpcHandle(hContext, dptr);
Finally, return the IPC handle to the driver with zeMemPutIpcHandle and free the device pointer in the sending process. If zeMemPutIpcHandle is not called, any actions performed by that call are eventually done by zeMemFree.
zeMemPutIpcHandle(hContext, hIpc); zeMemFree(hContext, dptr);
IPC with Physical Memory — Direct Handle#
This example demonstrates passing a physical memory handle directly to zeMemGetIpcHandle without
any prior virtual address reservation or mapping. The physical handle is cast to void* and
passed directly as the ptr argument. No VA mapping is needed in the sending process.
The receiving process gets a virtual address assigned automatically when it opens the handle.
Sending process:
// Create a physical memory object on the sending device size_t pageSize; size_t allocationSize = 1048576; // 1MB zeVirtualMemQueryPageSize(hContext, hDevice, allocationSize, &pageSize); size_t physicalSize = align(allocationSize, pageSize); ze_physical_mem_desc_t pmemDesc = { ZE_STRUCTURE_TYPE_PHYSICAL_MEM_DESC, nullptr, 0, // flags physicalSize }; ze_physical_mem_handle_t hPhysicalMem; zePhysicalMemCreate(hContext, hDevice, &pmemDesc, &hPhysicalMem); // Cast the physical memory handle directly to void* — no VirtualMemReserve // or VirtualMemMap is required in the sending process. ze_ipc_mem_handle_t hIPC; zeMemGetIpcHandle(hContext, (void*)hPhysicalMem, &hIPC); // NOTE: Transferring IPC handles is not a Level Zero API. The application is responsible // for sending the handle to the receiving process using its preferred out of band method // (e.g., Shared memory, TCP/IP, fabric, etc.) // Cleanup in sending process (after receiving process has closed its handle) zeMemPutIpcHandle(hContext, hIPC); zePhysicalMemDestroy(hContext, hPhysicalMem);
Receiving process:
// NOTE: Receiving IPC handles is not a Level Zero API. The application is responsible // for receiving the handle from the sending process using its preferred out of band method // (e.g., Shared memory, TCP/IP, fabric, etc.) ze_ipc_mem_handle_t hIPC; // Opening the handle assigns a new VA in this process for the physical memory. // No VirtualMemReserve/VirtualMemMap is needed in the receiving process. void* dptr = nullptr; zeMemOpenIpcHandle(hContext, hDevice, hIPC, 0, &dptr); // dptr is now a valid device pointer backed by the sender's physical memory // Cleanup in receiving process zeMemCloseIpcHandle(hContext, dptr);
IPC with Physical Memory — Mapped VA as IPC Source#
This example demonstrates a scenario where the sending process maps physical memory to a virtual address and then creates an IPC handle from that mapped VA. The IPC handle represents the single underlying physical memory object; only one physical memory object may be associated with an IPC handle at a time.
Sending process:
// Create a physical memory object size_t pageSize; size_t allocationSize = 1048576; // 1MB zeVirtualMemQueryPageSize(hContext, hDevice, allocationSize, &pageSize); size_t physicalSize = align(allocationSize, pageSize); ze_physical_mem_desc_t pmemDesc = { ZE_STRUCTURE_TYPE_PHYSICAL_MEM_DESC, nullptr, 0, // flags physicalSize }; ze_physical_mem_handle_t hPhysicalMem; zePhysicalMemCreate(hContext, hDevice, &pmemDesc, &hPhysicalMem); // Reserve VA and map the physical memory to it in this (parent) process void* mappedPtr = nullptr; zeVirtualMemReserve(hContext, nullptr, physicalSize, &mappedPtr); zeVirtualMemMap(hContext, mappedPtr, physicalSize, hPhysicalMem, 0, ZE_MEMORY_ACCESS_ATTRIBUTE_READWRITE); // Create an IPC handle from the mapped VA in this process. // The IPC handle encapsulates the physical memory object that mappedPtr is backed by. ze_ipc_mem_handle_t hIPC; zeMemGetIpcHandle(hContext, mappedPtr, &hIPC); // mappedPtr can be used for local compute work while also being shared via IPC // NOTE: Transferring IPC handles is not a Level Zero API. The application is responsible // for sending the handle to the receiving process using its preferred out of band method // (e.g., Shared memory, TCP/IP, fabric, etc.) // ... use mappedPtr locally ... // Cleanup: wait for receiving process to close its handle first, // then release the IPC handle and free local resources. zeMemPutIpcHandle(hContext, hIPC); zeVirtualMemUnmap(hContext, mappedPtr, physicalSize); zeVirtualMemFree(hContext, mappedPtr, physicalSize); zePhysicalMemDestroy(hContext, hPhysicalMem);
Receiving process:
// NOTE: Receiving IPC handles is not a Level Zero API. The application is responsible // for receiving the handle from the sending process using its preferred out of band method // (e.g., Shared memory, TCP/IP, fabric, etc.) ze_ipc_mem_handle_t hIPC; // The driver assigns a new VA in the receiving process for the shared physical memory. void* dptr = nullptr; zeMemOpenIpcHandle(hContext, hDevice, hIPC, 0, &dptr); // dptr is now accessible in this process and backed by the sender's physical memory // Cleanup zeMemCloseIpcHandle(hContext, dptr);
Events#
The following code examples demonstrate how to use the event IPC APIs:
First, the event pool is created, packaged, and sent on the sending process:
// create event pool ze_event_pool_desc_t eventPoolDesc = { ZE_STRUCTURE_TYPE_EVENT_POOL_DESC, nullptr, ZE_EVENT_POOL_FLAG_IPC | ZE_EVENT_POOL_FLAG_HOST_VISIBLE, 10 // count }; ze_event_pool_handle_t hEventPool; zeEventPoolCreate(hContext, &eventPoolDesc, 1, &hDevice, &hEventPool); // get IPC handle and send to another process ze_ipc_event_pool_handle_t hIpcEvent; zeEventPoolGetIpcHandle(hEventPool, &hIpcEventPool); // NOTE: Transferring IPC handles is not a Level Zero API. The application is responsible // for sending the handle to the receiving process using its preferred out of band method // (e.g., Shared memory, TCP/IP, fabric, etc.)
Next, the event pool is received and un-packaged on the receiving process:
// NOTE: Receiving IPC handles is not a Level Zero API. The application is responsible // for receiving the handle from the sending process using its preferred out of band method // (e.g., Shared memory, TCP/IP, fabric, etc.) ze_ipc_event_pool_handle_t hIpcEventPool; // open event pool ze_event_pool_handle_t hEventPool; zeEventPoolOpenIpcHandle(hContext, hIpcEventPool, &hEventPool);
Each process may now refer to the same device event allocation via its handle:
Receiving process creates event at location
ze_event_handle_t hEvent; ze_event_desc_t eventDesc = { ZE_STRUCTURE_TYPE_EVENT_DESC, nullptr, 5, // index 0, // no additional memory/cache coherency required on signal ZE_EVENT_SCOPE_FLAG_HOST, // ensure memory coherency across device and Host after event signaled }; zeEventCreate(hEventPool, &eventDesc, &hEvent); // submit kernel and signal event when complete zeCommandListAppendLaunchKernel(hCommandList, hKernel, &args, hEvent, 0, nullptr); zeCommandListClose(hCommandList); zeCommandQueueExecuteCommandLists(hCommandQueue, 1, &hCommandList, nullptr);
Sending process creates event at same location
ze_event_handle_t hEvent; ze_event_desc_t eventDesc = { ZE_STRUCTURE_TYPE_EVENT_DESC, nullptr, 5, 0, // no additional memory/cache coherency required on signal ZE_EVENT_SCOPE_FLAG_HOST, // ensure memory coherency across device and Host after event signaled }; zeEventCreate(hEventPool, &eventDesc, &hEvent); zeEventHostSynchronize(hEvent, UINT32_MAX);
Note, there is no guaranteed address equivalence for the values of hEvent in each process.
To cleanup, first close the pool handle in the receiving process:
zeEventDestroy(hEvent); zeEventPoolCloseIpcHandle(&hEventPool);
Finally, return the IPC handle to the driver with zeEventPoolPutIpcHandle and free the event pool in the sending process. If zeEventPoolPutIpcHandle is not called, any actions performed by that call are eventually done by zeEventPoolDestroy.
zeEventDestroy(hEvent); zeEventPoolPutIpcHandle(hContext, hIpcEventPool); zeEventPoolDestroy(hEventPool);
Peer-to-Peer Access and Queries#
Peer to Peer API’s provide capabilities to marshal data across Host to Device, Device to Host and Device to Device. The data marshalling API can be scheduled as asynchronous operations or can be synchronized with kernel execution through command queues. Data coherency is maintained by the driver without any explicit involvement from the application.
Cards may be linked together within a node by a scale-up fabric and depending on the configuration, the fabric can support remote access, atomics, and data copies.
The following Peer-to-Peer functionalities are provided through the API:
Check for remote memory access capability between two devices/subdevices: zeDeviceCanAccessPeer
The following rules apply to zeDeviceCanAccessPeer queries
A device/subdevice is always its own peer, i.e. it can always access itself.
Query remote memory access, atomic capabilities, logical & physical bandwidth & latency for peer-to-peer: zeDeviceGetP2PProperties + Bandwidth Extension Properties.
The following rules apply to zeDeviceGetP2PProperties queries
A device/subdevice is always its own peer, i.e. it can always access itself and also do so atomically.
Copy data between devices over peer-to-peer fabric: zeCommandListAppendMemoryCopy
Both zeDeviceCanAccessPeer & zeDeviceGetP2PProperties return the same information - do two devices support peer-to-peer access? zeDeviceGetP2PProperties provides more detail than zeDeviceCanAccessPeer, such as support for atomics, bandwidths, latencies, etc…
P2P Access to Physical Memory on Another Device#
When a physical memory object resides on one device and needs to be accessed from another device, the physical memory must first be mapped to a virtual address before it can be used in an append operation (e.g., zeCommandListAppendMemoryCopy, zeCommandListAppendLaunchKernel) or in a residency call (zeContextMakeMemoryResident).
This cross-device physical memory access is only valid if zeDeviceCanAccessPeer returns success for the two devices involved. Attempting to use physical memory from a device without verified P2P access results in undefined behavior.
The following example demonstrates accessing physical memory allocated on hDevice1 from a
command list created on hDevice0, where P2P access between the two devices is supported:
// Verify P2P access from hDevice0 to hDevice1 ze_bool_t canAccess = ZE_FALSE; zeDeviceCanAccessPeer(hDevice0, hDevice1, &canAccess); assert(canAccess == ZE_TRUE); // Create a physical memory object on hDevice1 size_t pageSize; size_t allocationSize = 1048576; // 1MB zeVirtualMemQueryPageSize(hContext, hDevice1, allocationSize, &pageSize); size_t physicalSize = align(allocationSize, pageSize); ze_physical_mem_desc_t pmemDesc1 = { ZE_STRUCTURE_TYPE_PHYSICAL_MEM_DESC, nullptr, 0, // flags physicalSize }; ze_physical_mem_handle_t hPhysicalMem1; zePhysicalMemCreate(hContext, hDevice1, &pmemDesc1, &hPhysicalMem1); // Reserve a VA range and map the physical memory from hDevice1 to a VA // accessible from hDevice0 (requires P2P support). void* peerPtr = nullptr; zeVirtualMemReserve(hContext, nullptr, physicalSize, &peerPtr); zeVirtualMemMap(hContext, peerPtr, physicalSize, hPhysicalMem1, 0, ZE_MEMORY_ACCESS_ATTRIBUTE_READWRITE); // Allocate a local buffer on hDevice0 for the copy destination void* localPtr = nullptr; zeMemAllocDevice(hContext, &deviceAllocDesc, physicalSize, 0, hDevice0, &localPtr); // peerPtr can now be used in a command list on hDevice0 via P2P access zeCommandListAppendMemoryCopy(hCommandList0, localPtr, peerPtr, physicalSize, nullptr, 0, nullptr); zeCommandListClose(hCommandList0); zeCommandQueueExecuteCommandLists(hCommandQueue0, 1, &hCommandList0, nullptr); zeCommandQueueSynchronize(hCommandQueue0, UINT64_MAX); // Cleanup zeVirtualMemUnmap(hContext, peerPtr, physicalSize); zeVirtualMemFree(hContext, peerPtr, physicalSize); zePhysicalMemDestroy(hContext, hPhysicalMem1); zeMemFree(hContext, localPtr);
P2P with Multiple Physical Memory Objects from Different Devices Mapped to the Same VA#
An application may map physical memory objects from different devices into a contiguous or adjacent virtual address range. The device that owns the command list or command queue determines which device is the “home” device for each access:
Accesses to VA regions backed by physical memory on the command list’s own device are serviced locally.
Accesses to VA regions backed by physical memory on another device are serviced via P2P, and are only valid if zeDeviceCanAccessPeer returns success for those two devices.
This pattern is useful for applications that want to present a unified VA space over heterogeneous physical memory, letting the hardware transparently route each access based on the backing device.
The following example creates a contiguous VA range backed by physical memory from two different
devices (hDevice0 and hDevice1). A command list on hDevice0 operates on the combined
range; the first half is local, and the second half is remote (P2P):
// Verify P2P access between the two devices ze_bool_t canAccess = ZE_FALSE; zeDeviceCanAccessPeer(hDevice0, hDevice1, &canAccess); assert(canAccess == ZE_TRUE); size_t pageSize; size_t halfSize = 1048576; // 1MB per segment zeVirtualMemQueryPageSize(hContext, hDevice0, halfSize, &pageSize); size_t segmentSize = align(halfSize, pageSize); size_t totalSize = segmentSize * 2; // Create physical memory on hDevice0 (local segment) ze_physical_mem_desc_t pmemDesc0 = { ZE_STRUCTURE_TYPE_PHYSICAL_MEM_DESC, nullptr, 0, segmentSize }; ze_physical_mem_handle_t hPhysMem0; zePhysicalMemCreate(hContext, hDevice0, &pmemDesc0, &hPhysMem0); // Create physical memory on hDevice1 (remote segment, accessed via P2P) ze_physical_mem_desc_t pmemDesc1 = { ZE_STRUCTURE_TYPE_PHYSICAL_MEM_DESC, nullptr, 0, segmentSize }; ze_physical_mem_handle_t hPhysMem1; zePhysicalMemCreate(hContext, hDevice1, &pmemDesc1, &hPhysMem1); // Reserve a contiguous VA range large enough to hold both segments void* vaBase = nullptr; zeVirtualMemReserve(hContext, nullptr, totalSize, &vaBase); // Map first half of the VA range to hDevice0's physical memory (local) zeVirtualMemMap(hContext, vaBase, segmentSize, hPhysMem0, 0, ZE_MEMORY_ACCESS_ATTRIBUTE_READWRITE); // Map second half of the VA range to hDevice1's physical memory (P2P) void* vaSecondHalf = (uint8_t*)vaBase + segmentSize; zeVirtualMemMap(hContext, vaSecondHalf, segmentSize, hPhysMem1, 0, ZE_MEMORY_ACCESS_ATTRIBUTE_READWRITE); // A command list created on hDevice0 can use both halves of the VA range. // - Accesses to vaBase..vaBase+segmentSize are local to hDevice0. // - Accesses to vaSecondHalf..vaSecondHalf+segmentSize go via P2P to hDevice1. // This is valid because canAccess == ZE_TRUE for (hDevice0, hDevice1). zeCommandListAppendMemoryFill(hCommandList0, vaBase, &pattern, sizeof(pattern), totalSize, nullptr, 0, nullptr); zeCommandListClose(hCommandList0); zeCommandQueueExecuteCommandLists(hCommandQueue0, 1, &hCommandList0, nullptr); zeCommandQueueSynchronize(hCommandQueue0, UINT64_MAX); // Cleanup zeVirtualMemUnmap(hContext, vaBase, segmentSize); zeVirtualMemUnmap(hContext, vaSecondHalf, segmentSize); zeVirtualMemFree(hContext, vaBase, totalSize); zePhysicalMemDestroy(hContext, hPhysMem0); zePhysicalMemDestroy(hContext, hPhysMem1);